
소개
한국어 지문의 질문에 대한 적합한 답변을 생성하는 MRC 모델 설계
과정
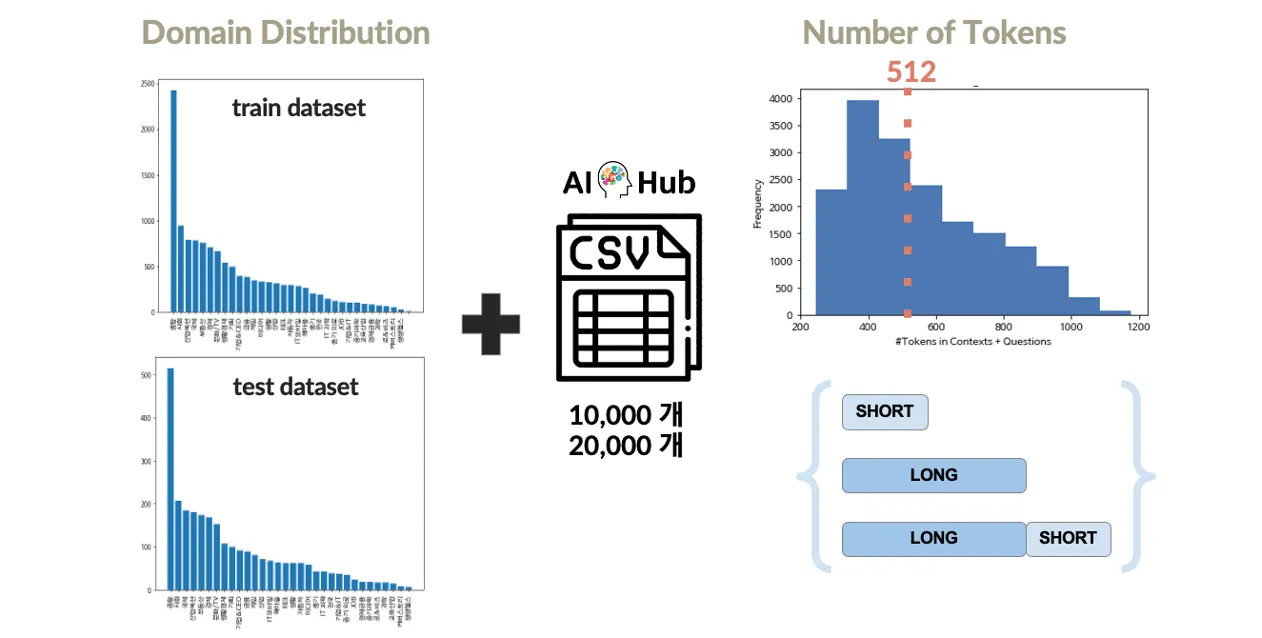
Train과 Test 데이터셋 간 도메인 분포 차이를 해결하기 위해 AIHub 데이터를 증강
BERT와 RoBERTa 모델을 학습하여 성능 비교 및 최적 모델 선정
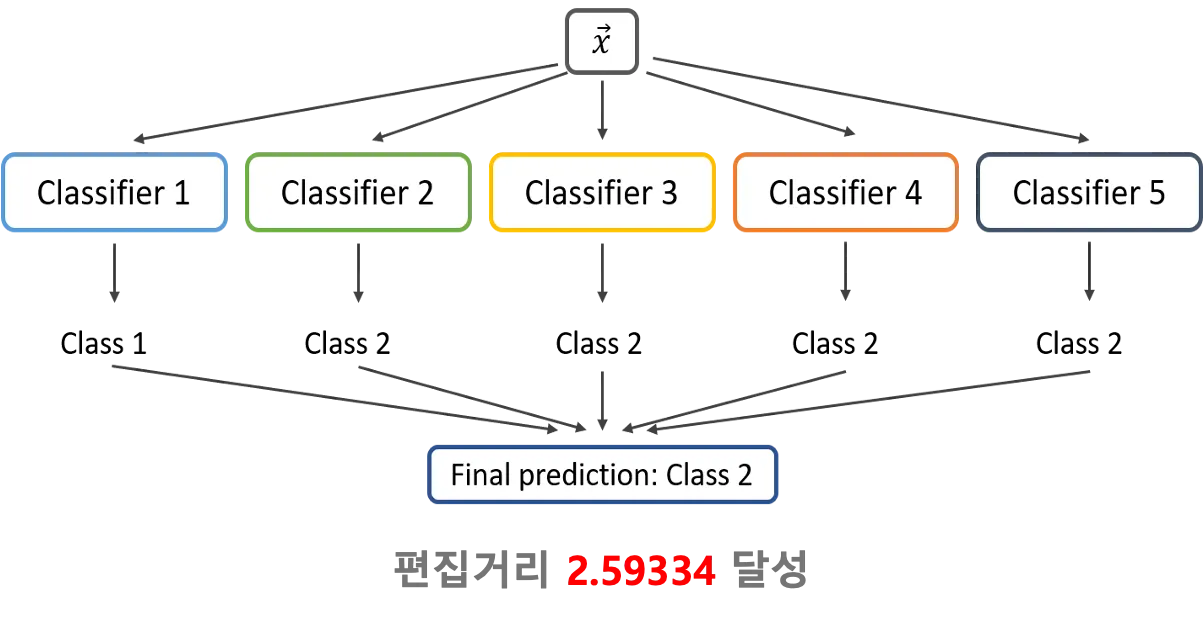
하이퍼파라미터 튜닝과 Hard Voting 앙상블 기법을 통해 모델 성능 최적화 진행
역할 및 담당
Aihub 자료 제공, test labeling 및 Metric(Levenstein) 측정 코드작성, 발표 자료 제작
결과
편집거리 2.59 도달
교육과정 Kaggle 대회에서 8팀 중 1위 차지
EDA 및 전처리
AIHub 데이터를 활용한 데이터 증강과 토큰 길이 기반 전처리를 수행
Train/Dev Split 비율에 따른 성능을 비교함
•
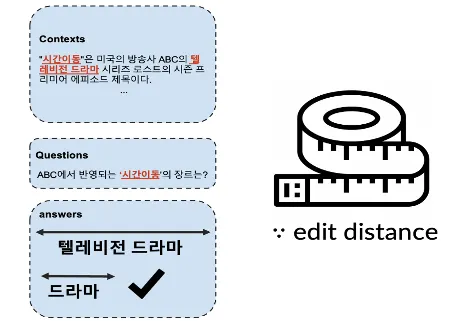
동일 Context와 Question에 대한 다른 Answers 문제:
동일 지문과 질문에 대해 여러 답변이 존재하는 약 1만 개의 데이터 확인
평가 지표가 답변 길이에 민감하므로, 가장 짧은 답변만을 선택한 방식과 모든 답변을 활용한 방식을 비교
결과적으로 모든 데이터를 활용한 방법이 더 나은 성능을 기록
•
Data Augmentation:
AI Hub MRC 데이터를 활용하여 짧은 문장, 긴 문장, 두 가지 형태 모두를 추가하는 방식으로 실험
짧은 문장만을 추가했을 때 가장 높은 성능을 달성했으나, 도메인 불일치로 인해 증강 후 성능 저하 발생
•
Split Ratio:
Train과 Dev 데이터를 8:2로 분할한 경우와 모든 데이터를 Train으로 사용하는 경우 비교
모든 데이터를 Train에 활용한 경우 더 나은 성능을 기록
모델링
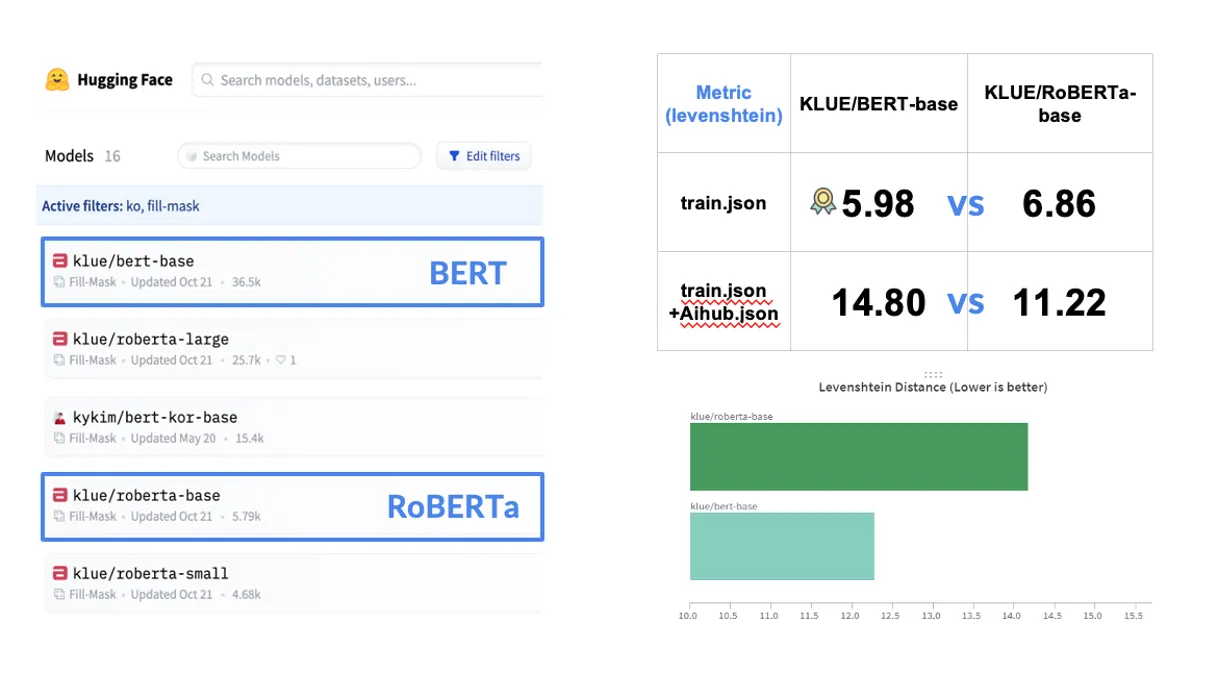
Pretrained 모델로 KLUE/BERT-base와 KLUE/RoBERTa-base를 사용하여 성능을 비교
기본 BERT모델에서 더 나은 결과를 보임
•
BERT-base vs RoBERTa-base 비교:
◦
주어진 데이터만 학습 시 BERT가 더 높은 성능을 기록: 5.98
◦
데이터 증강 후에는 RoBERTa가 더 많은 파라미터로 인해 더 좋은 성능을 보임: 11.22
•
모델 한계:
Extraction-based 모델 외에 KoELECTRA와 T5와 같은 다른 모델을 실험하지 못한 점은 한계로 남음
성능 최적화
편집거리와 EM Score를 평가 지표로 활용해 하이퍼파라미터 튜닝을 진행
RAdam, 스케줄러, 후처리(답변 길이 조정)로 성능을 최적화
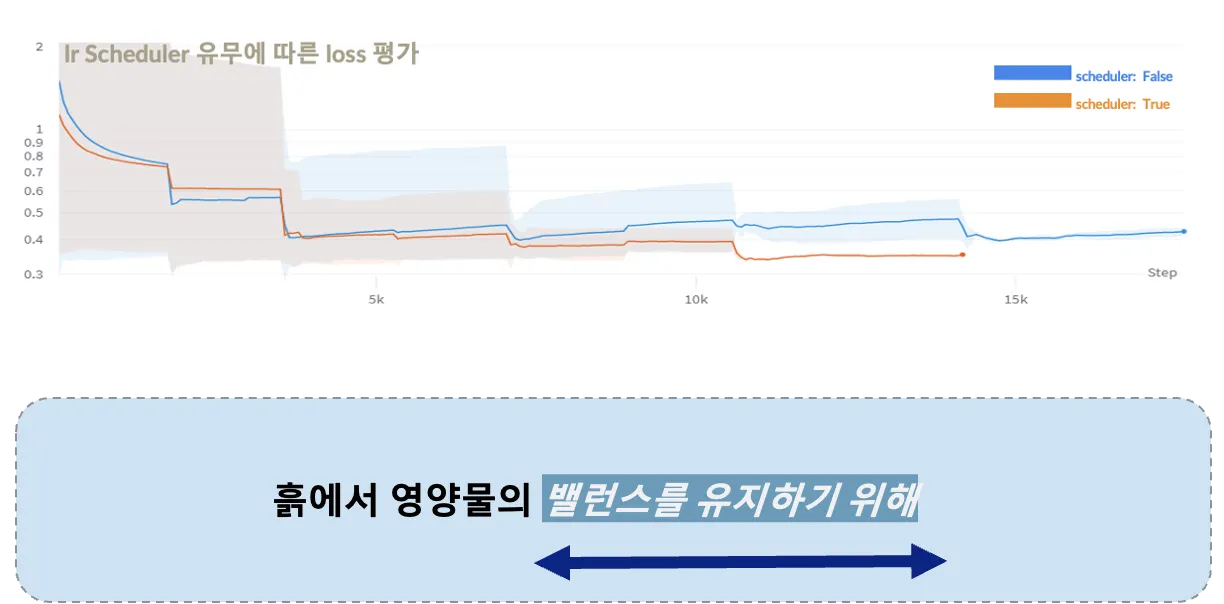
•
parameter Tuning:
◦
Batch Size, Epoch, Optimizer, Learning Rate, Scheduler 등 실험
◦
Radam, Scheduler 성능향상
•
답변 길이 자르기:
◦
답변 길이를 잘라 후처리
◦
뒤에서 12글자를 자른 경우 성능향상: 6.7 → 2.9
결과
Hard Voting 방식의 앙상블 기법을 적용해 성능을 추가적으로 향상
최종적으로 편집거리 2.59를 기록하고 Kaggle 대회에서 8팀 중 1위를 차지