


개요
소개
포켓몬 대결 데이터를 기반으로 승률 예측 모델을 설계
과정
Null값 처리, 승률에 영향을 미치는 주요 컬럼 분석, 범주형 데이터 라벨 인코딩 진행
KNN, SVM, Decision Tree, Random Forest, XGBoost 모델 학습
650회 이상의 테스트를 통해 모델 성능을 검증
XGBoost 모델과 컬럼조합(Speed, Attack, Defense, Generation, Type, Legendary)
역할 및 담당
데이터 전처리, 모델학습(Random Forest, XGBoost), 발표
결과
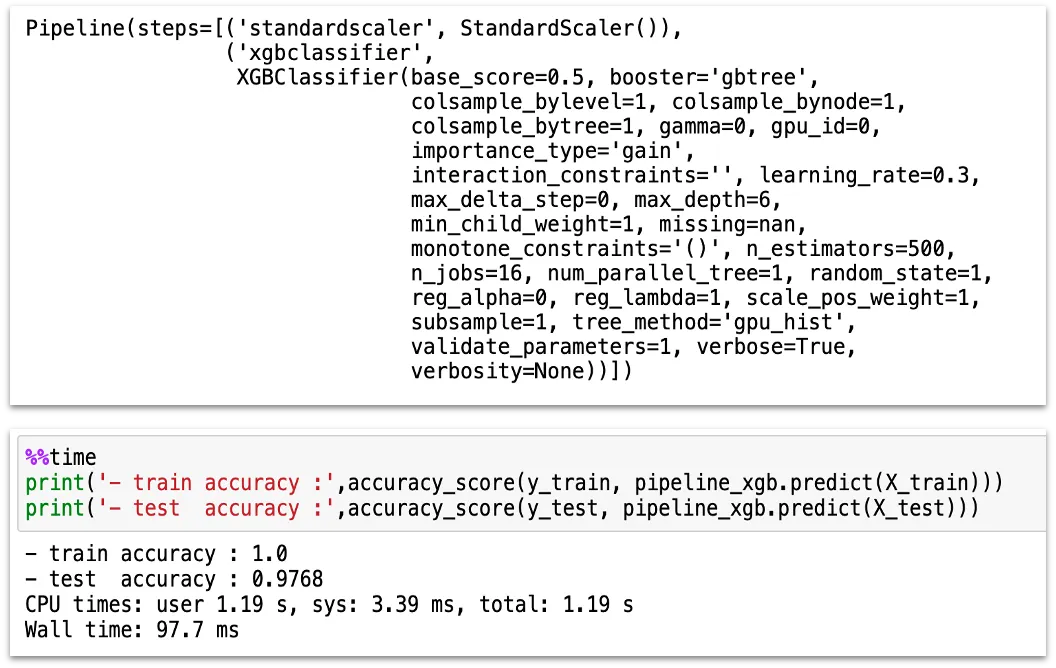
정확도 0.9768 달성
데이터 확인
데이터를 확인하여 분석 및 모델링에 적합한 상태인지 검토하고, 데이터의 특성과 구조를 파악
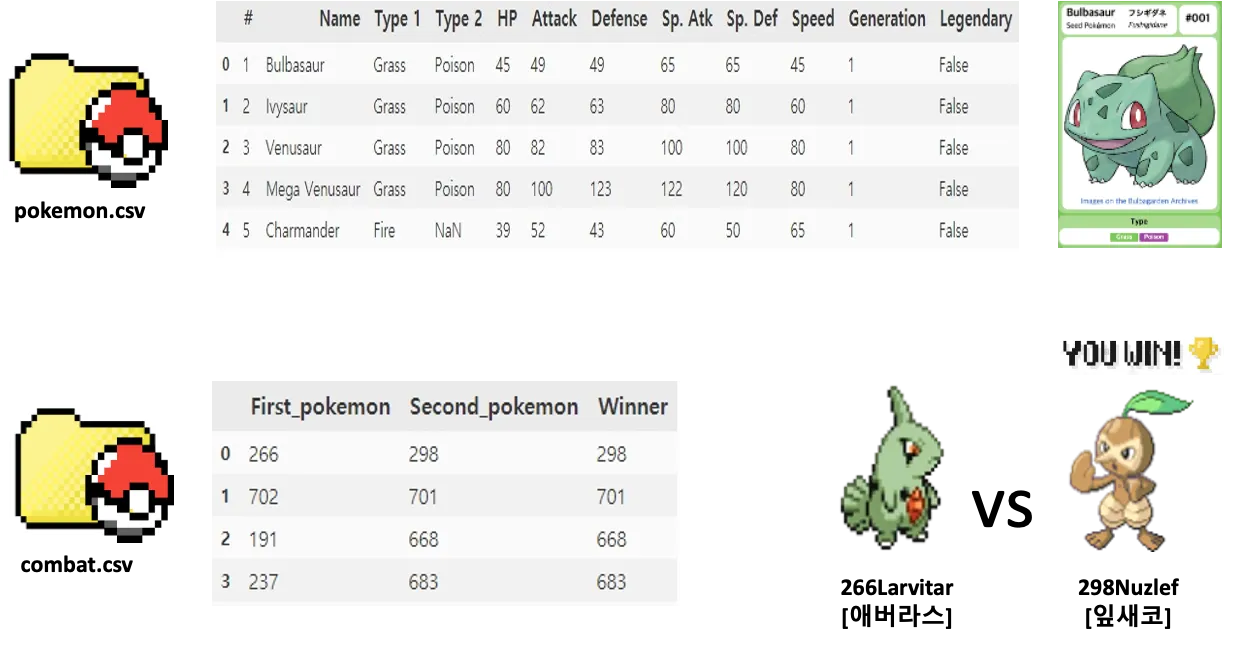
포켓몬 능력치와 대결 정보를 포함한 두 데이터를 사용하여 승리 예측을 위한 데이터 구조와 주요 컬럼을 확인
•
pokemon.csv 포켓몬의 정보(능력치):
포켓몬의 이름, 타입, HP, 공격력, 방어력, 공격스피드, 방어스피드, 스피드, 세대, 전설의 포켓몬 여부
•
combat.csv 포켓몬 대결 정보:
첫번째 포켓몬(First_pokemon)과 두번째 포켓몬(Second_pokemon)이 대결하여 승리한 포켓몬은 Winner 컬럼을 통해 확인 가능
데이터 전처리
데이터의 결측값 및 이상치를 처리하고, 머신러닝 모델에 적합한 형태로 변환하여 예측 정확도를 높이기 위함
결측값 처리, 승률에 영향을 미치는 주요 컬럼 분석, 라벨인코딩, 분석 및 모델 학습에 필요한 데이터셋을 준비
•
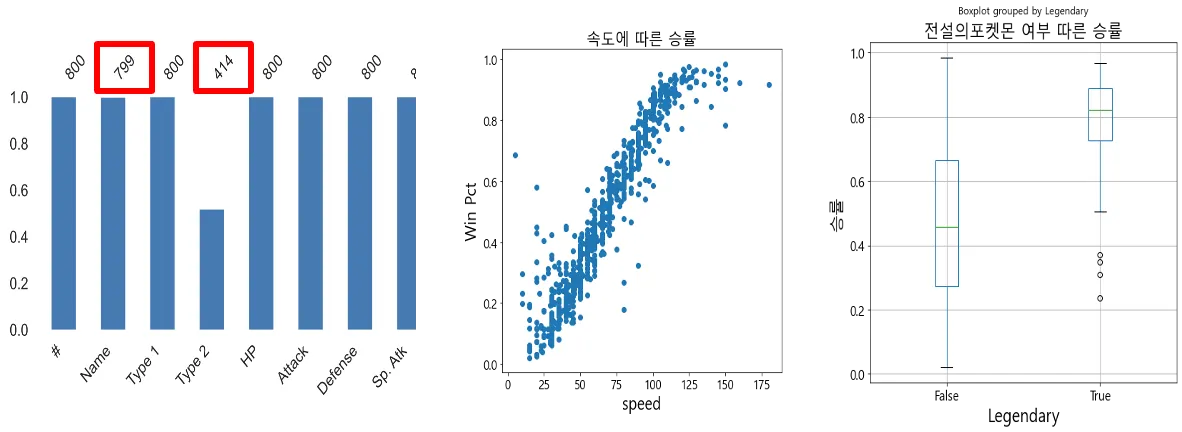
Name, Type2 필드 Null값 존재:
1)Name (799개): 망키의 진화형 성원숭의 능력치와 동일함을 확인
2)Type2 (414개): Type2 필드의 Null값은 순수 포켓몬을 의미하므로 문제가 되지 않음
•
승률에 영향 미치는 컬럼:
속도(Speed), 전설의 포켓몬(Legendary)
모델링
데이터를 활용해 다양한 머신러닝 알고리즘으로 학습시키고 성능을 비교하여 최적의 예측 모델을 도출하는 과정
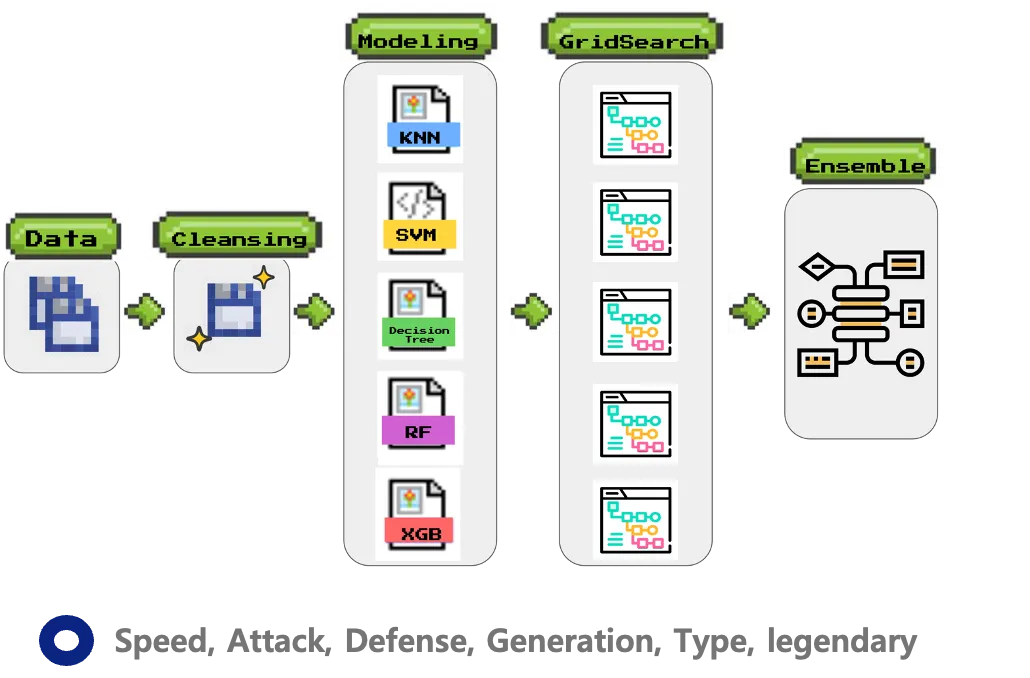
KNN, SVM, Random Forest, XGBoost 등의 모델을 비교하고, 주요 특징 조합을 활용하여 XGBoost 모델에서 96.97%의 성능을 달성
•
1단계: 모델 성능 확인
모델 | 성능 |
KNN | 0.91424 |
SVM | 0.91576 |
Decision Tree | 0.91632 |
Random Forest | 0.956 |
XGBoost | 0.96968 |
•
Speed, Attack, Defense, Generation, Type, legendary
앙상블
앙상블이란, 여러 모델의 예측 결과를 결합하여 단일 모델보다 더 높은 성능과 안정성을 확보하는 기법
앙상블 기법을 통해 ROC-AUC와 Feature Importance를 분석, 최종적으로 XGBoost 모델에서 97.68%의 최고 정확도를 달성
•
3단계: 앙상블
모델 | 성능 |
XGBoost | 0.9768 |
Ensemble | 0.9567 |