

개요
소개
Yelp 리뷰에서 긍·부정을 감정을 분류하는 모델을 설계
과정
데이터 전처리 단계에서 중복 데이터와 클래스 불균형 문제
Transformer 기반 모델(BERT, RoBERTa, ALBERT, SCI-BERT)을 비교하여 모델 선정
Learning Rate Scheduler와 Hard-voting 앙상블 기법을 적용해 최적화
역할 및 담당
Pretrained Model 탐색, 모델 학습(BERT, RoBERTa), 발표 자료 제작
결과
정확도 0.992를 달성하며, 교육과정 Kaggle 대회에서 8팀 중 1위를 차지
EDA 및 전처리
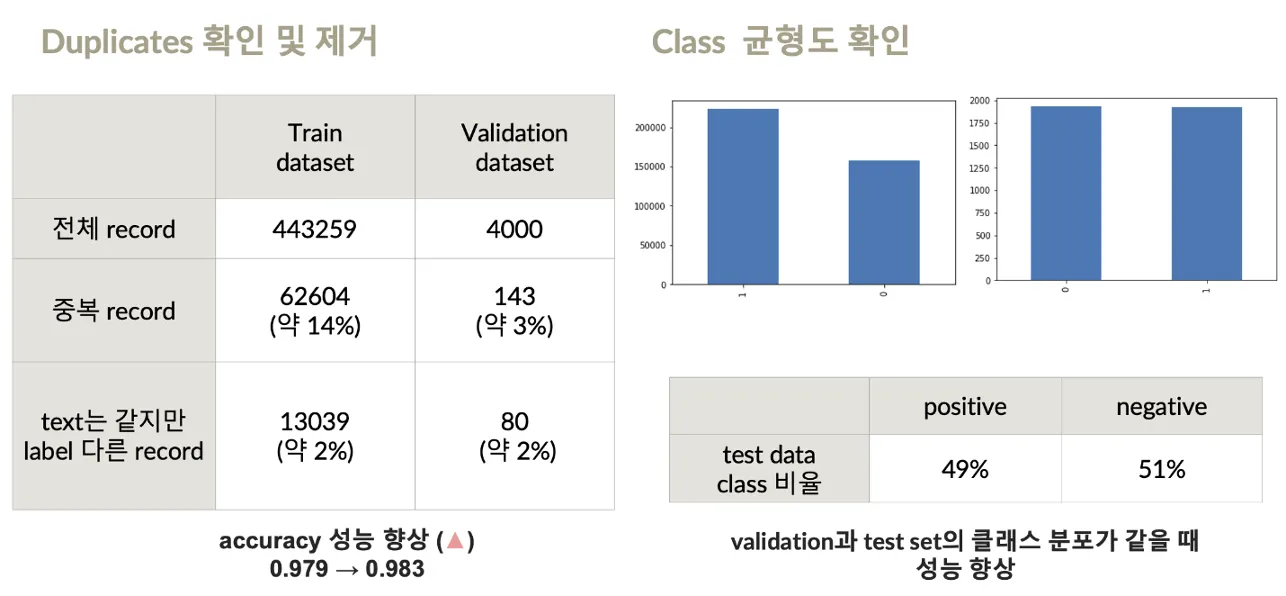
EDA를 통해 중복 데이터와 동일 텍스트-다른 라벨 데이터를 식별하고 제거
클래스 불균형 문제를 분석하여 원래 데이터셋 비율을 유지하는 방향으로 전처리를 진행
•
데이터 삭제:
중복 데이터(14%),동일 텍스트-다른 라벨 데이터(2%) 제거
baseline 모델의 성능향상: 0.979 → 0.983
•
클래스 불균형 문제:
Train 데이터의 클래스 불균형 문제를 해결하기 위해 shuffling을 시도했으나 성능이 하락
validation과 test 데이터의 클래스 분포가 유사할 때 성능 향상
모델링
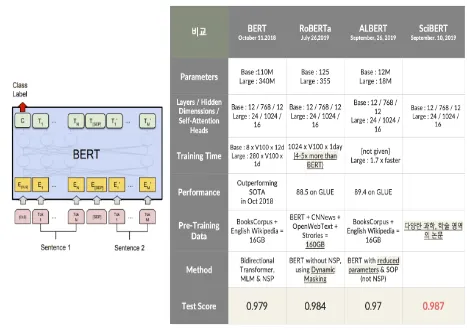
BERT를 기반으로 RoBERTa, ALBERT, SCI-BERT 등의 변형 모델을 사용하여 성능을 비교
각 모델의 특성과 데이터셋의 적합성을 분석하여 최적의 성능을 달성
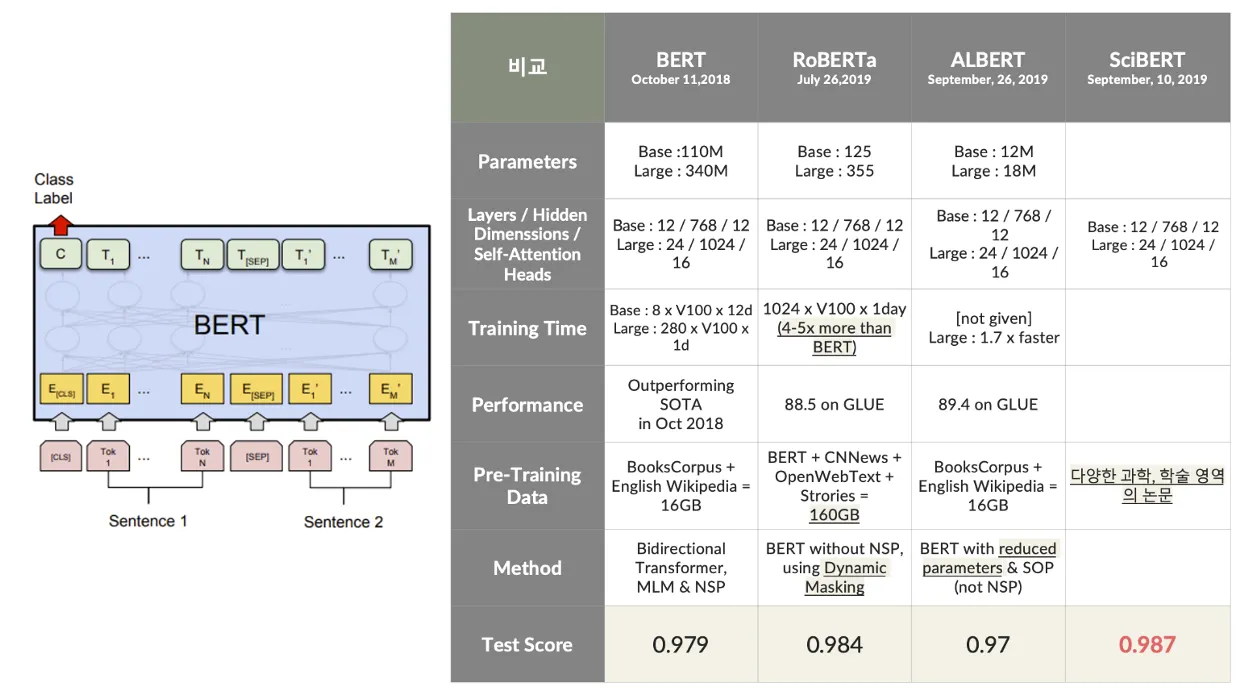
모델링 과정에서 BERT를 기반으로 RoBERTa, ALBERT, SCI-BERT 등의 변형 모델을 실험함
•
RoBERTa (0.984) 더 많은 학습 데이터와 dynamic masking 기법을 활용해 높은 성능
•
ALBERT (0.97) 경량화를 통해 효율성을 확보
•
SCI-BERT (0.987) 학술 데이터 중심 pre-training 모델예상과 달리 높은 성능 기록
성능 최적화
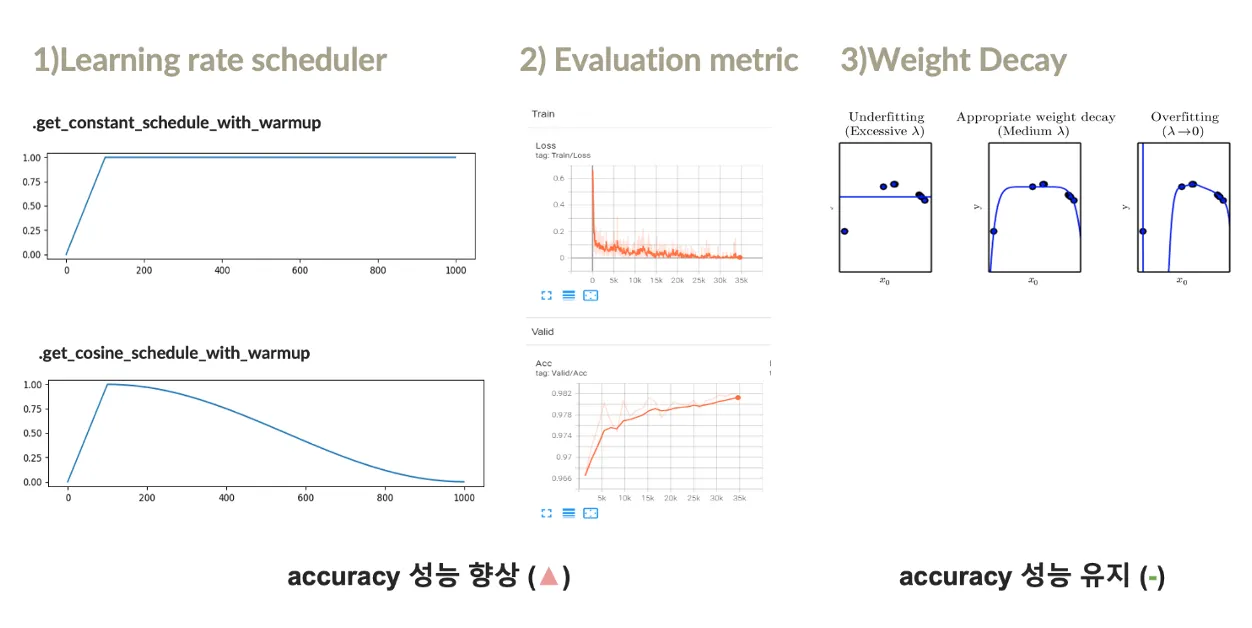
모델의 성능을 최적화하기 위해 학습률 스케줄러, 평가 지표 개선, weight decay, hard-voting 앙상블 적용
모델의 정확성을 향상시키고 overfitting 문제를 해결하고자 함
•
Leaning rate Scheduler:
warm-up 후 일정한 유지를 위해 스케줄 방식 적용
constant schedule, cosine schedule 두 방식 모두 성능 향상에 효과적
•
Evaluation metric:
accuracy도 평가 지표로 활용, Tensorboard로 학습 과정을 시각화
best model 저장방식으로 정확도 높임
•
Weight Decay:
오버핏 해결위해 weight decay 적용, 성능 개선에는 크게 기여하지 못함
결과
Hard Voting 방식의 앙상블 기법을 적용해 성능을 추가적으로 향상
최종적으로 0.990 성능향상, Kaggle 대회에서 8팀 중 1위를 차지
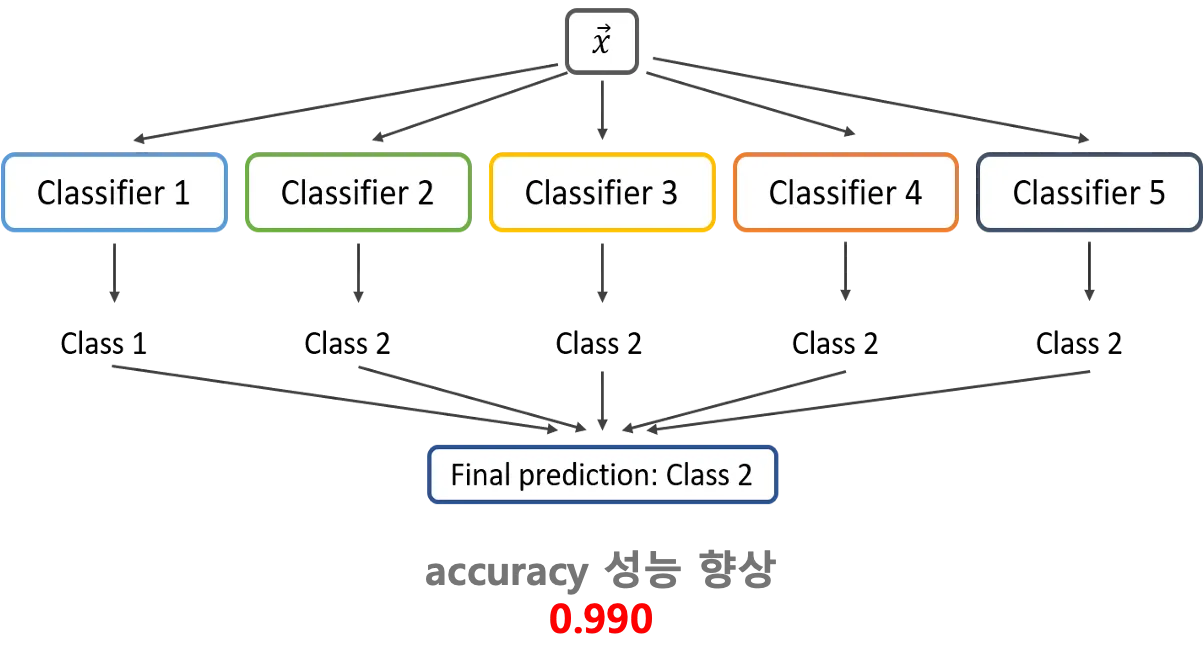
•
Ensemble(Hard Voting)
최고 점수를 기록한 3개의 모델- 다른 라벨 분포 2개 RoBERTa 모델
위의 모델을 결합하여 성능 향상