

주제
배경 및 목표에 대해 1문장으로 기재

파일과 디렉터리
파일시스템은 파일과 디렉터리를 관리하며, 파일과 디렉터리는 보조기억장치(하드디스크, SSD 등)에 저장된 데이터의 논리적 단위이다. 이를 통해 사용자는 데이터를 체계적으로 저장, 접근, 관리할 수 있다.
파일
•
파일은 하드 디스크나 SSD 같은 보조기억장치에 저장된 관련 정보의 집합이다.
•
의미 있는 정보를 모은 논리적 단위로, 운영체제가 이를 관리한다.
파일의 속성(attribute)
파일과 관련된 부가정보로, 운영체제가 이를 유지 및 관리한다. 운영체제마다 유지하는 파일 속성은 조금씩 차이는 있지만 대표적인 속성은 다음과 같다.
속성이름 | 의미 |
파일의 이름 | 파일을 식별하기 위한 이름 |
위치 및 크기 | 파일이 저장된 물리적 위치와 크기 정보 |
권한 정보 | 파일 접근 권한(소유자, 생성자 등) |
유형 | 파일의 종류(예: 텍스트, 실행파일 등) |
시각 정보 | 생성 날짜, 마지막 접근 날짜, 마지막 수정 날짜 |
디렉터리 데이터 | 해당 디렉터리 내부에 포함된 파일 및 디렉터리 정보 |
파일의 유형(types)
파일은 운영체제에 종류에 따라 구분된다.
파일 유형 | 대표적인 확장자 |
실행파일 | exe, com, bin |
목적파일 | obj, o |
소스코드 파일 | c, cpp, cc, java, asm, py |
워드 프로세스 파일 | xml, rtf, doc, docx |
라이브러리 파일 | lib, a, so, dll |
멀티미디어 파일 | mpeg, mov, mp3, mp4, avi |
백업/보관 파일 | rar, zip, tar |
•
확장자: 파일 이름 뒤에 붙으며, 운영체제가 파일의 종류를 인식하는 힌트 역할을 한다.
파일 연산
운영체제는 파일을 처리하기 위해 다음과 같은 시스템 호출을 제공한다.
파일 접근 방법 | C언어의 POSIX 표준함수 | 설명 |
파일 생성 | create() | 새로운 파일 생성 |
파일 삭제 | unlink() | 파일 삭제 |
파일 열기 | open() | 파일 핸들을 반환하여 읽기/쓰기 작업 준비
열기는 파일 접근 준비 단계, 핸들 반환 및 리소스를 확보 |
파일 닫기 | close() | 파일 핸들 반환 및 리소스 해제 |
파일 읽기 | read() | 파일 데이터를 읽음
파일 내용 데이터 읽기. 핸들을 통해 데이터를 읽음 |
파일 쓰기 | write() , mmap() | 파일에 데이터를 기록 |
디렉터리
파일들을 체계적으로 관리하기 위한 구조적 단위로, 트리구조(Tree Structure)로 구성되며, 최상위 디렉터리를 루트 디렉터리(/)라 부른다.
경로의 종류
•
절대경로(absolute path): 루트 디렉터리(/)부터 시작하는 경로
•
상대경로(relative path): 현재 디렉터리(.)부터 시작하는 경로
디렉터리 연산
운영체제는 디렉터리 관리 및 접근을 위해 다음과 같은 시스템 호출을 제공한다.
디렉터리 접근 방법 | POSIX 표준함수 | 설명 |
디렉터리 생성 | mkdir() | 새로운 디렉터리 생성 |
디렉터리 삭제 | rmdir() | 디렉터리 삭제 |
디렉터리 열기 | opendir() | 디렉터리 접근 준비 단계
디렉터리 접근 권한 확인 및 핸들 반환
- 반환값: 핸들 포인터(DIR *) |
디렉터리 닫기 | closedir() | 열린 디렉터리 핸들을 닫아 리소스 누수를 방지 |
디렉터리 읽기 | readdir()
| 디렉터리 항목(파일/디렉터리 정보)을 순차적으로 읽는다.
- 반환값: 반환되는 항목은 일반적으로 파일이름이나 메타데이터를 포함하며, 디렉터리 끝에 도달하면 NULL을 반환한다. |
현재 디렉터리 변경 | chdir() | 현재 작업 디렉터리를 변경 |
디렉터리 엔트리(행)
디렉터리는 파일의 집합을 나타내는 특별한 파일이다. 디렉터리는 내부적으로 테이블 형태로 구성되어 포함된 파일 정보를 관리한다.
디렉터리 엔트리(행)는 다음과 같은 정보를 포함한다:
•
파일 이름
•
파일의 위치를 추적할 수 있는 간접적 정보(데이터 블록 위치 등)
즉, 디렉터리 엔트리를 통해 해당 디렉터리에 무엇이 담겨 있는지, 보조기억장치 어디에 있는지를 직간접적으로 알 수 있다.
파일과 디렉터리의 저장형태
•
파일: 보조기억장치에 테이블 블록 형태로 저장
•
디렉터리: 파일시스템 마다 다르지만, 일반적으로 파일이름과 메타데이터를 테이블 형태로 저장
13.4. protection
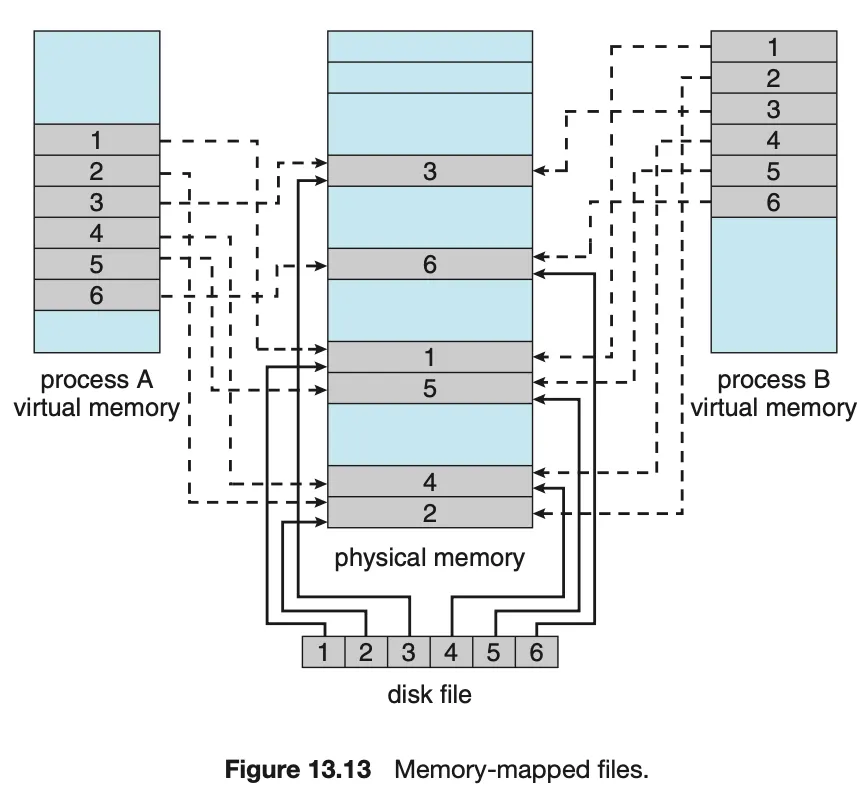
메모리 매핑 파일(Memory-Mapped Files)
일반적인 파일I/O 문제점:
•
기존의 open(), read(), write() 시스템 호출은 매번 디스크 접근 및 시스템 호출을 필요로 하기 때문에 오버헤드가 크다.
•
메모리 매핑 파일은 가상 메모리 기술과 연계해 이러한 오버헤드를 줄이고 파일을 메모리처럼 처리한다.
메모리 매핑 파일은 파일I/O를 효율적으로 처리하기 위해 파일을 가상 메모리에 매핑하는 기술이다. 이를 통해 디스크에 있는 파일 데이터를 메모리처럼 접근할 수 있으며, 성능 향상 및 간단한 파일 접근 방식을 제공한다. 특히 대규모 파일 처리 및 프로세스 간 데이터 공유가 중요한 애플리케이션에서 매우 유용하다.
메모리 매핑 방식
1.
디스크 블록을 메모리 페이지에 매핑한다.
2.
최초 접근 시 페이지 폴트를 통해 필요한 페이지를 메모리에 적재한다.
3.
이후 읽기/쓰기 작업은 메모리를 직접 액세스하듯 처리한다.
4.
파일 변경 내용을 파일이 닫힐 때 보조기억장치에 기록한다.
동작 원리
•
메모리에 매핑된 파일의 데이터는 물리 메모리에서 관리되며, 일반적인 메모리 접근 방식으로 읽기와 쓰기가 이루어진다.
•
파일 변경 내용은 즉시 디스크에 기록되지 않고, 메모리 상태를 기반으로 나중에 저장된다.
•
메모리 부족 시 변경된 데이터는 스왑 공간에 기록되어 데이터 손실을 방지한다.
장점
•
디스크 I/O와 시스템 호출을 줄여 파일 액세스 속도 증가
•
데이터를 메모리에 접근하듯이 처리
•
여러 프로세스 간 데이터를 쉽게 공유
단점
•
대규모 파일 매핑 시 메모리 부족 현상이 발생할 수 있음
•
다중 프로세스 간 데이터 동기화를 추가적으로 관리해야 함
•
적절한 메모리 관리 및 동기화 메커니즘을 설계해야 함
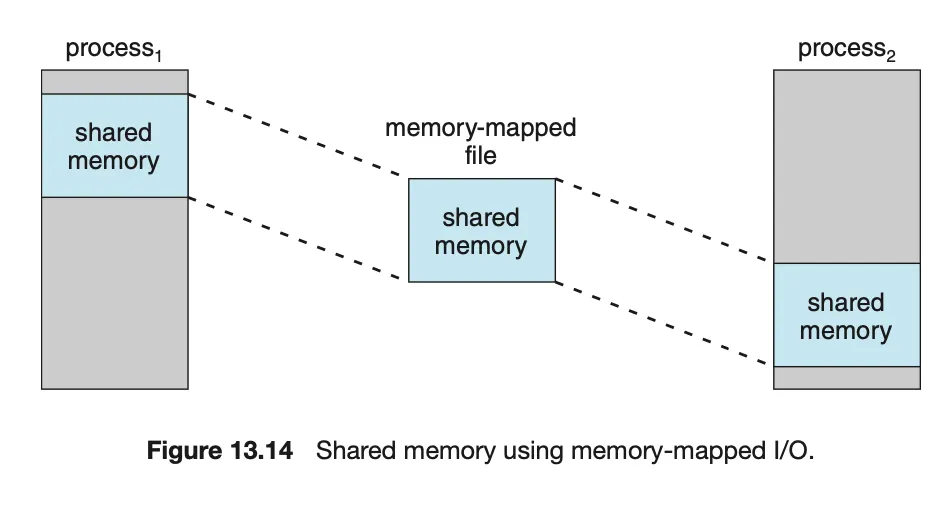
공유 메모리와 메모리 매핑
•
다중 프로세스 간 데이터 공유:
◦
여러 프로세스가 동일한 파일을 매핑하여 같은 데이터를 공유할 수 있다.
◦
모든 프로세스의 가상 메모리 맵이 동일한 물리적 메모리를 참조한다.
•
COW 기능:
◦
읽기 전용으로 데이터를 공유하되, 데이터 변경 시 각 프로세스가 독립적인 복사본을 생성 해야한다.
◦
데이터 공유와 독립성을 동시에 보장한다.
•
공유 메모리와 통신:
◦
메모리 매핑된 파일을 공유 메모리 처럼 사용 가능하다.
◦
프로세스 간 통신(IPC)을 위해 메모리 매핑된 파일을 활용
메모리 매핑 파일의 주요 시스템 호출
•
POSIX 환경(리눅스/유닉스):
◦
mmap(): 파일을 메모리에 매핑
◦
mumap(): 매핑 해제
실습: 메모리 맵 파일을 사용해서 파일 데이터 변경해보기.
14장: 파일시스템 구현
데이터와 파일 내용을 액세스 할수 있도록 하는 핵심 메커니즘.
파일 사용 구조화, 저장 공간 할당, 사용된 공간 회수, 데이터 위치 추적, 운영체제와 보조기억 장치간 인터페이스, 성능 문제와 관련된 다양한 고려사항
•
파일 시스템 및 디렉터리 구조
•
블록 할당 및 빈 블록 관리
•
파일 시스템 효율성과 성능 ← 성능 향상, 오버헤드 줄이는 기술
◦
파일 시스템 성능 고려사항: 접근시간(데이터를 읽거나 쓰는 속도), 신뢰성(데이터무결성과 장애 발생 시 복구 가능성 보장), 확장성(대규모 데이터와 다중 사용자 액세스 지원)
•
파일 시스템 장애 복구
•
구체적 사례 ← WAFL파일 시스템
14.1 파일 시스템 구조와 관리
디스크와 비휘발성 메모리(NVM)의 역할
파일 시스템은 주로 디스크와 비휘발성 메모리(NVM)에 상주하며, 이는 보조기억 장치의 역할을 수행한다. 파일 시스템은 디스크와 NVM의 블록 단위를 활용해 데이터를 효율적으로 전송하며, 두 저장 매체의 차이를 고려해 설계 및 최적화가 필요하다.
특징 | 디스크 | 비휘발성 메모리(NVM) |
쓰기 방식 | 블록 단위로 다시 쓰기 가능 | 다시 쓰기가 불가능하며 덮어쓰기 전에 삭제 필요 |
접근 방식 | 임의 블록에 직접 접근 가능.
순차적 및 임의 접근 모두 지원 | 임의 접근 가능.
성능 특성이 디스크와 다름 |
파일 간 전환 | 파일 간 전환이 간단 | 파일 간 전환 지원 |
블록 크기 | 보통 512바이트 또는 4096바이트 | 보통 4096바이트 |
전송 방식 | 블록 단위 전송 | 블록 단위 전송 |
•
파일 시스템은 효율적인 I/O처리를 위해 데이터를 블록 단위로 전송한다.
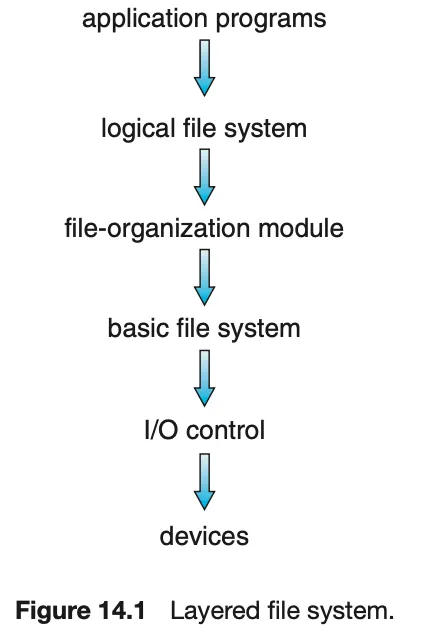
파일 시스템의 계층 구조
파일 시스템은 계층적 설계로 구성되어 있으며, 각 계층은 하위 계층의 기능을 활용하여 상위 계층의 기능을 구현한다. 이러한 구조는 파일 시스템의 유연성, 유지보수성, 확장성을 높이는데 기여한다.
계층 | |
애플리케이션 | - 사용자의 명령(파일 생성, 읽기, 쓰기 등)을 처리하고,이를 하위 계층으로 전달
- 애플리케이션은 이 요청을 시스템 콜(예:read(), write())로 전달
- 시스템 콜은 운영체제 커널의 논리 파일 시스템 계층으로 전달
예시: read(file.txt, offset=1024, length=512) |
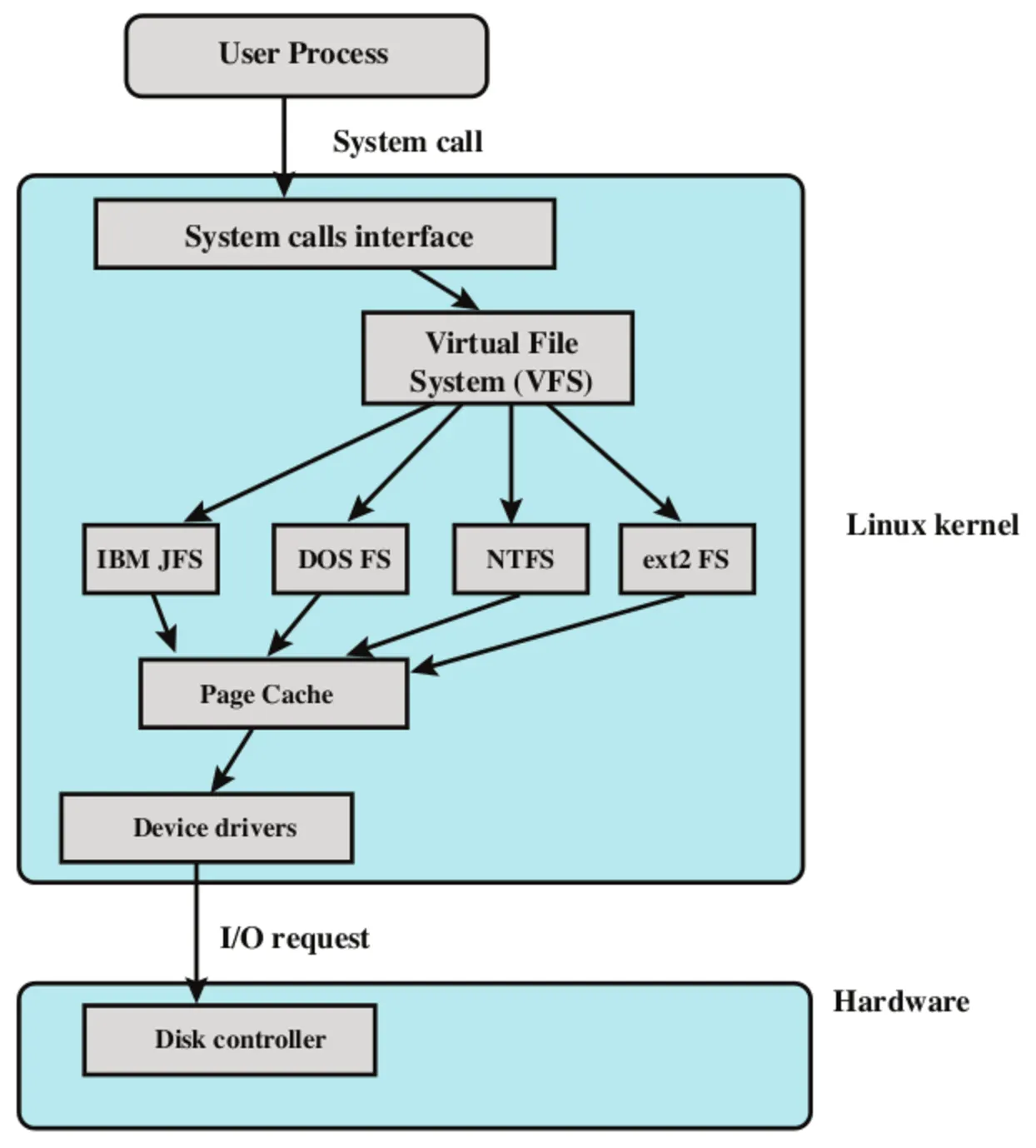
논리 파일 시스템
logical File System | - 파일의 메타데이터(FCB)와 디렉터리 구조를 참조하여 파일의 논리적 위치를 확인
- 파일 이름과 디렉터리 구조 관리
- 파일 접근 권한 및 보안 처리
- 구성요소: VFS(Virtual File system)
처리 과정
1. 파일 이름 확인: file.txt가 디렉터리 구조에 있는 지 확인
2. FCB 로드: 해당 파일의 파일 제어 블록(FCB)을 로드
3. 권한 확인 : 요청자가 읽기 권한을 가졌는지 확인
4. 논리 블록 정보 : 파일의 논리 블록 위치를 확인
5 .파일의 논리 블록 번호를 파일 조직 모듈에 전달 |
파일 조직 모듈
File Organization Module | - 파일 데이터를 디스크의 물리적 블록으로 매핑
- 메타데이터와 데이터 저장방식 관리
- 구성요소: 파일 시스템 구현(ext4, btrfs, NTFS 등)
- 운영체제의 파일 시스템이 논리적 파일 시스템()과 저장 장치의 물리적 블록 사이를 연결하는 역할
- 파일의 논리 블록 번호 → 물리 블록 번호로 변환
- (파일 쓰기 요청 시)빈 블록 관리
처리 과정
1. 논리 블록 → 물리 블록 변환: 논리 블록 번호를 참조하여 디스크 상의 물리적 위치(헤드, 섹터, 트랙)를 계산
2. (쓰기 요청 시)블록 할당: 빈 블록을 검색하여 파일에 할당
3. 물리적 블록 번호를 기본파일 시스템으로 전달- |
기본 파일 시스템
Basic File system | - 디스크의 특정 블록에 대한 읽기/쓰기 요청을 처리
- 블록 단위로 데이터를 처리하며, 요청을 I/O제어 계층으로 전달
- 디스크 블록을 읽거나 쓰는 작업을 관리
- 디스크 블록의 읽기/쓰기 요청을 I/O 제어 계층으로 전달
- 데이터 버퍼링(Buffer):
- 파일 시스템 요청을 논리적 블록주소()로 변환
- 물리적 디스크 블록의 읽기/쓰기를 위한 인터페이스 제공
- 구성요소: Block Device(예:HDD, SSD, NVMe)
처리 과정
1. 요청된 데이터를 임시로 저장할 메모리 버퍼 할당
2. 물리적 블록 번호와 read_block 또는 write_block명령 생성
3. I/O 제어 계층에 명령 전달 |
I/O 제어 | - 디바이스 드라이버와 인터럽트 핸들러를 통해 하드웨어장치와 통신
- 고수준 명령어(예:read_block)을 하드웨어가 이해할 수 있는 저수준 명령으로 변환
- 디스크 드라이버를 통해 저장 장치와 통신
- 디스크 요청 스케줄링(예:I/O 큐 관리) 및 캐싱 처리
- 구성요소: Disk Drivers(예: SATA 드라이버, NVMe드라이버)
처리과정
1. 드라이버 호출: 디스크 컨트롤러에 블록 번호와 명령 전달
2. 인터럽트 처리: 작업 완료 시 하드웨어로부터 인터럽트를 받아 응답 처리
3. 물리적 블록의 데이터 또는 상태 정보를 기본 파일 시스템으로 전달 |
물리적 장치(device) | - 디스크의 특정 블록에 물리적으로 접근하여 데이터를 읽거나 씀
- 물리적 디크스 장치와 직접적인 상호작용
- 저장장치 하드웨어의 동작 제어(헤드 이동, 데이터 전송 등)
- 구성요소: Disk Controller(예: SATA Controller, NVMe Controller, SCSI controller)
처리 과정
1. 디스크 헤드 이동: 요청된 블록이 있는 트랙으로 디스크 헤드 이동
2. 블록 읽기/쓰기: 디스크의 회전 지연(latency)을 기다린 후 데이터 전송
3. 데이터 또는 작업 상태를 I/O 제어 계층으로 응답 |
장점
•
다양한 파일 시스템에 동일한 코드 재사용 가능
•
특정 계층만 파일시스템에 종속적이므로 유지보수가 용이
단점
•
계층 구조로 인한 운영체제 오버헤드 발생
14. 2 파일 시스템 작업 File-System Operations
파일 시스템 작업은 디스크와 메모리 상의 다양한 구조를 활용하여 파일 생성, 접근, 수정, 삭제와 같은 작업을 수행한다. 이러한 작업은 파일 시스템 계층 구조에서 시스템 호출(open(), write() 등)을 통해 구현된다. 파일 시스템 작업은 디스크 상 구조와 메모리 상 구조의 유기적인 협력을 통해 이루어 진다. 이 과정에서 데이터 구조와 계층별 처리 방식을 활용하여 효율적이고 안정적인 파일 관리가 가능해진다.
파일 시스템 구조
디스크 상 구조
디스크에는 파일 시스템을 운영하기 위한 메타데이터와 관련 정보가 저장된다.
1.
부트 컨트롤 블록(Boot Control Block)
•
운영체제를 부팅하기 위한 정보를 저장한다.
•
위치: 볼륨의 첫번째 블록
◦
UNIX: Boot Block
◦
NTFS: Partition Boot Section
2.
볼륨 컨트롤 블록(Volume Control Block)
•
파일 시스템의 세부 정보를 저장한다.
•
포함정보: 볼륨 블록 수, 블록 크기, 빈 블록 개수 및 포인터, 빈 FCB 개수 및 포인터
← 이쪽에 superblock 관련된 내용이 있는데.. 번역된다고 해서 다 좋은게 아닌듯하다..
3.
디렉터리 구조(Directory structure)
•
파일 이름과 FCB를 매핑하여 파일을 체계적으로 조직한다.
◦
UNIX: 파일 이름 → inode 번호
◦
NTFS:MFT에 저장
1.
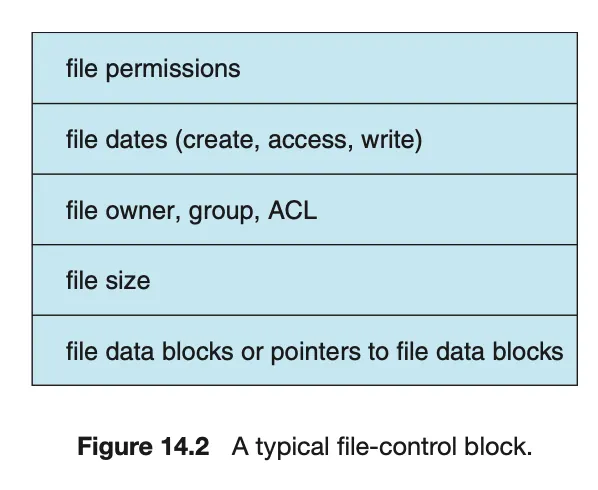
파일 제어 블록(FCB, File-control Block)
•
개별 파일의 메타데이터를 관리한다.
•
포함정보:
◦
파일 소유권, 크기, 권한, 날짜
◦
디렉터리 항목과 매핑 된 고유 식별 번호
•
NTFS 구현: FCB정보는 MFT의 관계형 데이터베이스 구조로 관리
메모리 상 구조
메모상 데이터 구조는 파일 시스템 관리 및 성능 최적화를 위해 사용된다.
1.
마운트 테이블(mount table)
•
현재 마운트 된 볼륨의 정보를 저장
2.
디렉터리 캐시(directory-structure cache)
•
최근 액세스된 디렉터리 정보를 캐싱
•
마운트된 볼륨의 디렉터리 위치를 포함할 수 있음
3.
시스템 전역 열린 파일 테이블(system-wide open-file table)
•
현재 열린 모든 파일의 FCB 복사본 및 관련 정보 저장
4.
프로세스 별 열린 파일 테이블(per-process open-file table)
•
각 프로세스가 열어둔 파일의 시스템 전역 테이블 항목에 대한 포인터와 추가 정보 포함
5.
버퍼(beffer)
•
디스크로 부터 읽거나 디스크에 기록 중인 파일 시스템 블록을 임시로 저장
파일 작업 처리 과정
새 파일 생성
1.
논리 파일 시스템 호출
•
create() 호출로 파일 이름과 경로를 전달한다. //<경로>에 <파일 이름>으로 파일을 생성할거야!!
2.
FCB 할당←
•
3.
디렉터리 업데이트
파일 열기
1.
파일 이름 검색
•
디렉터리 구조에서 해당 파일 이름을 매핑된 FCB를 검색
2.
FCB 로드
•
FCB를 시스템 전역 열린 파일 테이블에 복사
•
프로세스별 열린 파일 테이블에 항목 추가
파일 닫기
14.2.2 usage
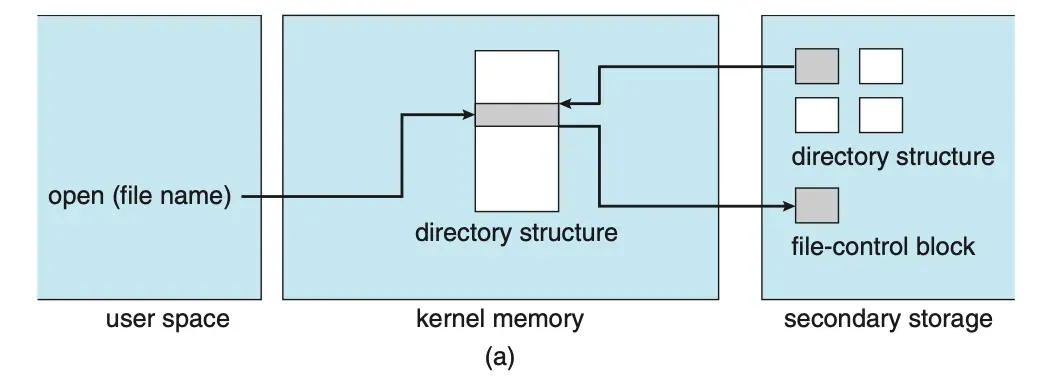
14.3 Directory implementation
운영체제는 사용자가 파일에 접근하고 관리할 수 있도록 파일 이름과 메타 데이터를 논리적 구조를 제공하며, 이를 디렉터리 구조로 구현한다. 운영체제는 검색, 삽입, 삭제 성능과 디스크 매핑 효율성을 높이기 위해 선형 리스트, 해시 테이블, 트리 구조 등 다양한 자료 구조를 활용한다. 대표적인 선형 리스트(Linear List)와 해시 테이블(Hash Table)을 살펴보자.
•
선형 리스트:
간단하고 구현이 용이하지만, 디렉터리가 커질수록 성능이 떨어짐.
작은 시스템이나 디렉터리에서 적합하다.
•
해시 테이블:
검색 속도가 매우 빠르지만, 충돌 처리 및 테이블 크기 조정 문제를 해결해야 함.
대규모 디렉터리에 적합하다.
디렉터리의 트리 구조와 디렉터리 구현
14.3.1 선형리스트 Linear List
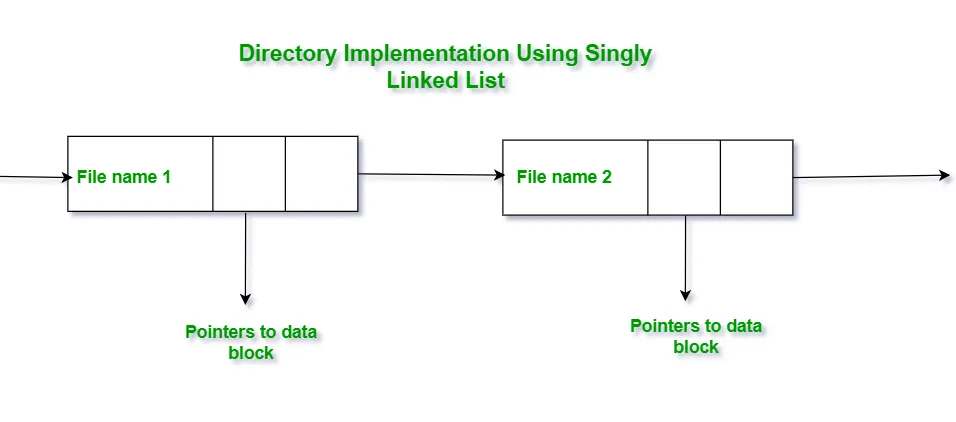
파일 이름과 데이터 블록에 대한 포인터를 저장한 단순한 리스트 형태이다. 파일 생성, 삭제, 검색 등의 작업이 리스트를 순회하며 이루어진다.
•
새 파일을 만들려면, 전체 목록을 검사하여 새 디렉터리가 이전에 존재하는지 확인한다. → 새 디렉터리를 리스트 끝이나 리스트 시작부분에 추가할 수 있다.
•
파일을 삭제하려면, 먼저 삭제할 파일의 이름으로 디렉터리를 검색한다. 검색 한 후 해당 파일에 할당된 공간을 해제하여 해당 파일을 삭제할 수 있다.
장점
•
구조가 단순하여 프로그래밍 구현이 간단하다.
•
삭제된 항목을 처리 방법 다양하게 제공한다.
◦
삭제된 항목을 “사용하지 않음”으로 표시 (예: 특수이름, 비유효 i-node 번호 사용)
◦
삭제된 항목을 별도의 빈 항목 리스트로 관리
◦
마지막 항목을 삭제된 위치로 이동하여 리스트를 축소
단점
•
파일 검색 시 리스트를 처음부터 끝까지 탐색해야 하므로 비효율적이다.
•
디렉터리 접근이 잦은 경우 느릴 수 있다.
14.3.2 Hash Table
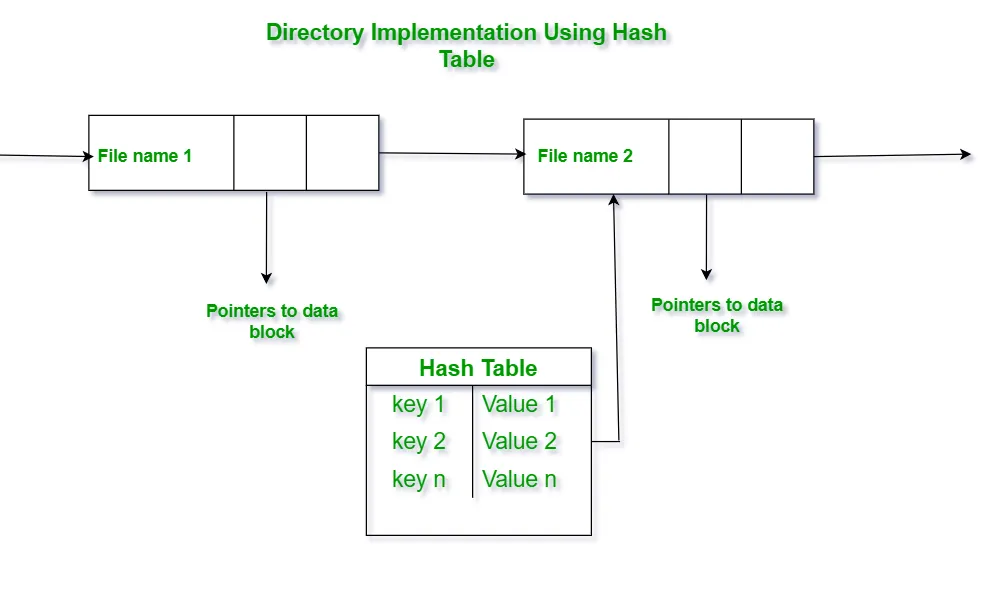
디렉터리 항목은 선형리스트에 저장되며, 해시 테이블을 추가로 사용하여 검색 속도를 개선한다.
파일 이름을 해시 함수로 변환 해 선형 리스트 내의 위치를 반환한다.
•
키(key): 파일 이름 또는 디렉터리 이름
•
값(value): 파일의 메타데이터, inode 번호, 디스크 블록 주소 등
실제 구현에서는 inode 번호를 값으로 사용하는 경우가 가장 일반적이다.
해시 테이블:
{
"file1.txt": inode 1001,
"file2.log": inode 1002,
"folder1": inode 1003
}
inode 1001:
{
디스크 블록: [102, 103],
크기: 2048 bytes,
권한: rw-r--r--,
소유자: user
}
Bash
복사
장점
•
선형 리스트에 비해 훨씬 빠른 검색 가능( 또는 근사치)
•
충돌 해결만 처리하면 삽입과 삭제가 비교적 간단
단점
•
충돌문제: 두 파일 이름이 동일한 해시 값을 가지면 충돌이 발생
•
해시 테이블 크기가 고정되어 확장성에 제약이 있음
•
테이블이 꽉 차거나 크기를 확장할 때 기존 항목을 새로운 해시 값에 따라 다시 매핑해야 한다. 계산 비용이 많이 든다.
충돌 해결 방법
1.
선형 탐색:
•
충돌 발생 시 다음 빈 슬롯을 순차적으로 찾음
•
단점: 클러스터링(인접 슬롯이 점점 차는 문제) 발생 가능
2.
체인 오버 플로우(Chained Overflow):
•
해시 테이블의 각 항목에 연결 리스트를 사용해 충돌된 항목을 저장
•
검색 속도는 약간 느려지지만 선형 리스트보다 효율적
기준 | 선형 리스트 | 해시 테이블 |
구현 난이도 | 단순하고 구현이 쉬움 | 충돌 처리 및 해시 함수 설계로 인해 다소 복잡 |
검색 시간 | 선형 검색 (O(n)) | 상수 시간 (O(1)), 충돌 시 약간 증가 |
삽입 시간 | 정렬된 경우 O(n),
그렇지 않으면 O(1) | O(1) |
삭제 시간 | 검색 후 삭제(O(n)) | O(1) (충돌 처리 후) |
공간 효율성 | 추가 메모리 필요 없음 | 추가 메모리 필요(해시 테이블 및 충돌 처리) |
확장성 | 작은 디렉터리에 적합 | 큰 디렉터리에서 성능이 뛰어남 |
충돌 처리 | 해당 없음 | 필요 (선형 탐색 또는 체인 오버플로우) |
15.3 파티셔닝과 마운팅
15.5 가상파일 시스템 Virtual File System
파일 할당 방법 (Allocation Methods)
빈공간 관리 Free-space Management
14.6 Efficiency & Performance
14.7 Recovery 복구
파일 시스템 구현 (ext4, XFS, Btrfs)
15.1 기타 파일 시스템
15.8 네트워크 파일 시스템
네트워크로 연결된 원격 디렉터리를 로컬에 마운트하여 사용하는 네트워크 파일 시스템이 있다. NFS(Network File System) CIFS(Common Internet File System)은 원격 호스트에 있는 파일 시스템을 로컬에 있는 파일 시스템처럼 조작할 수 있다.
•
NFS(Network File System) : 유닉스/리눅스 중심의 네트워크 파일 공유 프로토콜
•
CIFS(Common Internet File System): 윈도우 환경에서 SMB
•
CephFS : 대규모 분산 파일 시스템이나 필요한 클러스터 환경에 적합
특징 | NFS | CIFS | CephFS |
용도 | 유닉스/리눅스 중심 파일 공유 | Windows와의 파일 공유 | 대규모 분산 파일 시스템 |
프로토콜 | NFS (포트 2049) | SMB/CIFS (포트 445) | Ceph 클러스터 프로토콜 |
확장성 | 제한적 | 제한적 | 뛰어남 |
POSIX 호환 | 일부 제한 | 제한적 | 완전 호환 |
보안 | Kerberos, TLS 지원(NFSv4) | NTLM, Kerberos 지원 | 데이터 암호화 및 복제 지원 |
성능 | 네트워크 성능에 민감 | 네트워크 및 인증에 민감 | 대규모 클러스터에 최적화 |
복잡성 | 설정 간단 | 설정 복잡 | 설치 및 관리 복잡 |
NFS(Network File System)
NFS는 네트워크를 통해 원격 파일 시스템에 접근할 수 있도록 하는 프로토콜이다. 유닉스/리눅스 시스템에서 널리 사용된다. 원격 파일을 로컬 파일 시스템처럼 마운트하여 사용 가능하다.
•
클라이언트와 서버 아키텍처 기반
•
TCP, UDP를 모두 사용하며, 기본적으로 포트 2049를 사용
•
파일 잠금 및 동시성 제어를 지원(NFSv3, NFSv4에서 개선)
•
원격 파일 시스템을 투명하게 접근 가능
장점
•
여러 클라이언트에서 같은 데이터를 동시에 공유 가능
•
플랫폼 간 호환성(다양한 OS지원)
•
설정과 사용이 간단
단점
•
네트워크 성능에 민감
•
보안이 취약하므로 추가 설정 필요(NFSv4에서 개선)
# 원격 파일 시스템으로 마운트
sudo mount -t nfs <server_IP>:<remote_IP> <local_PATH>
Bash
복사
CIFS(Common Internet File System)
CIFS는 SMB(Server Message Block)프로토콜의 확장버전으로, 원격파일 및 디렉터리 장치 등에 접근할 수 있도록 설계되었다. Microsoft가 주도하여 Windows환경에서 널리 사용된다.
•
파일 공유, 프린터 공유, 네트워크 브라우징, 인증 등을 지원
•
TCP 445 포트 사용
•
데이터 암호화 및 인증 프로토콜(Kerberos, NTLM 등)지원
장점
•
Windows와 호환성 우수
•
파일 잠금 및 동시성 제어
•
자용자 인증 지원
단점
•
네트워크 성능 저하 가능
•
NFS에 비해 설정 복잡도가 높음
#CIFS 파일시스템 마운트
sudo mount -t cifs //<서버_IP>/<공유_이름> <로컬_경로> -o username=<사용자>,password=<비밀번호>
Bash
복사
CephFS
CephFS는 Ceph분산 스토리지 시스템에서 제공하는 POSIX호환 분산파일 시스템이다. 대규모 클러스터 환경에서 확장성을 제공하며, 고가용성과 고성능을 목표로 설계되었다.
•
분산 스토리지: 데이터를 여러 노드에 분산 저장하여 장애 복구와 확장성 제공
•
POSIX 호환: 기존 파일 시스템과 동일하게 사용 가능
•
CRUSH 알고리즘: 데이터 배치를 효율적으로 관리
•
블록 스토리지(RBD), 오브젝트 스토리지(RGW)와 통합 가능
장점
•
대규모 환경에서 뛰어난 확장성
•
데이터 복제 및 장애 복구
•
다양한 프로토콜과 통합 지원
단점
•
설치 및 관리 복잡
•
소규모 환경에서 과도한 리소스 사용
# CephFS 마운트
sudo mount -t ceph <Ceph_Monitor_IP>:<파일시스템 경로> <로컬_경로> -o name=<사용자>,secret=<키>
Bash
복사
쿼터
Q&A
Related Posts
Search



















