




배경 및 목표
Prometheus와 Alertmanager를 활용해 시스템 이상 상황을 모니터링하고, 실시간으로 경고 알림을 전송하여 문제를 신속히 파악하고 대응하는 데 목적이 있다. 네트워크와 서비스 상태에 대한 경고 규칙을 정의하고, 경고 테스트를 통해 설정을 검증한다.


Alertmanager Rule 지정
개발환경
항목 | 설정 |
Monitoring | - Prometheus (image: prom/prometheus)
- Grafana (image: grafana/grafana)
- Alertmanager (image: prom/alertmanager) |
Prometheus Exporter | - Nginx Exporter (image: nginx/nginx-prometheus-exporter)
- Node Exporter
- MySQL Exporter (image: prom/mysqld-exporter)
- Redis Exporter (image: oliver006/redis_exporter) |
Dash Board | - Nginx 대시보드
- Spring Boot 대시보드 템플릿 (ID: 4701)
- MySQL 대시보드 템플릿 (ID: 7362)
- Redis 대시보드 템플릿 (ID: 763) |
구조
/coupon-project/_monitoring/
├── docker-compose.yml
│
├── alertmanager/config/
│ └── alertmanager.yml
│
└── prometheus/config/
├── prometheus.yml
└── alerts.yml
YAML
복사
파일명 | 설명 |
docker-compose.yml | Docker Compose 설정 파일, Prometheus와 Alertmanager 컨테이너를 정의 |
alertmanager.yml | Alertmanager의 설정 파일
Slack과 같은 외부 서비스와의 통합 및 알림 경로를 설정 |
prometheus.yml | Prometheus 설정 파일
Alertmanager와의 연동, 데이터 수집 타겟 설정 및 경고 규칙 파일 연결 설정 |
alerts.yml | Prometheus의 경고 규칙 파일
조건에 따라 알림을 발생시키는 규칙(예: CPU 사용률 초과)을 정의 |
Rule 지정
1.
alerts.yml 규칙을 작성한다.
Prometheus의 알림 규칙(alert rules)은 특정 조건을 만족할 때 Alertmanager로 알림을 전송하는 역할을 한다. 이러한 규칙은 Prometheus의 메트릭(metric)과 표현식(expression)을 기반으로 작성되며, 조건이 충족되면 알림을 트리거(trigger) 한다.
couponService 관련 규칙
•
ServiceDown: 서비스 다운 경고
서비스 상태가 비정상적인 경우 발생하는 알림이다. up 메트릭은 서비스가 정상 상태인 경우 1을 반환하며, 서비스가 중단된 경우 0을 반환한다. up==0인 상태가 1분 이상 지속 될 경우 알림이 전송된다. 특정 서비스가 다운되거나 응답하지 않는 상태가 발생할 때 경고한다.
- alert: ServiceDown
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Service Down 서비스다운 경고"
description: "1분 동안 상태가 down이면 트리거.
The service {{ $labels.job }} on {{ $labels.instance }} is not responding (status: down)."
Dart
복사
•
HighCPUUsage CPU 사용률 경고
특정 서버의 CPU 사용률이 80%를 초과할 경우 발생하는 경고 알림이다. node_cpu_seconds_total 메트릭을 활용하여 CPU 사용률을 계산한다. mode=”idle”을 제외한 모든 CPU 사용 상태를 기준으로 고부하 상태로 인해 CPU 자원이 부족할 경우 알림이 전송된다.
- alert: HighCPUUsage
expr: clamp(1 - (sum(rate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) / sum(rate(node_cpu_seconds_total[5m])) by (instance)), 0, 1) * 100 > 80
for: 1m
labels:
severity: warning
annotations:
summary: "High CPU Usage Detected CPU 사용률 경고"
description: "초당 CPU 사용률 80% 초과하면 트리거.
CPU usage of {{ $labels.instance }} has exceeded 80% for the last minute. Current value: {{ $value }}%"
Dart
복사
NetworkAlert 관련 규칙
•
HighNetworkTraffic 네트워크 트래픽 과다 경고
네트워크 송수신 트래픽이 지나치게 높은 상태 일때 발생하는 알림이다. node_network_receive_bytes_total과 node_network_transmit_bytes_total 메트릭을 사용하여, 송수신 트래픽이 초당 100MB(100,000,000 bytes)초과하면 1분 동안 트리거된다. 예상치 못한 대량 트래픽, 네트워크 공격(DDoS)이 들어올 때 발생한다.
- alert: HighNetworkTraffic
expr: rate(node_network_receive_bytes_total[5m]) + rate(node_network_transmit_bytes_total[5m]) > 100000000
for: 1m
labels:
severity: critical
annotations:
summary: "High Network Traffic 네트워크 트래픽 과다 경고"
description: "5분 동안 송수신 바이트 초당 증가율이 100MB/s 초과하면 트리거.
Network traffic on {{ $labels.device }} exceeds 100 MB/s. Current rate: {{ $value }}."
Dart
복사
•
NetworkErrors 네트워크 에러 경고
네트워크 인터페이스에서 송수신 오류가 발생하는 알림이다. node_network_receive_errs_total과 node_network_transmit_errs_total 메트릭을 사용하여, 5분 동안 초당 네트워크 송수신 오류 수가 10이상 발생하면 알림이 전송된다. 네트워크 하드웨어 문제, 라우팅 오류, 또는 패킷 충돌 등의 원인으로 송수신 오류가 발생할 때 발생한다.
- alert: NetworkErrors
expr: (rate(node_network_receive_errs_total[5m]) + rate(node_network_transmit_errs_total[5m])) > 10
for: 1m
labels:
severity: critical
annotations:
summary: "High Network Errors 네트워크 에러 경고"
description: "5분 동안 송수신 네트워크 오류의 초당 증가율이 10 초과하면 트리거.
Network errors detected on {{ $labels.instance }}. Total errors: {{ $value }}."
Dart
복사
•
NetworkPacketDrops 네트워크 드롭 경고
네트워크에서 송수신 패킷이 손실되는 비율이 높아질 경우 발생하는 알림이다. node_network_receive_drop_total과 node_network_transmit_drop_total 메트릭을 사용하여 5분 동안 초당 드롭된 패킷 수가 10 이상 발생하면 알림이 전송된다. 네트워크 과부하, 트래픽 큐 관리 실패 또는 패킷 충돌로 인해 손실 된 패킷이 많아질 때 발생한다.
- alert: NetworkPacketDrops
expr: (rate(node_network_receive_drop_total[5m]) + rate(node_network_transmit_drop_total[5m])) > 10
for: 1m
labels:
severity: warning
annotations:
summary: "High Network Packet Drops 네트워크 드롭 경고"
description: "5분 동안 송수신 패킷 드롭의 초당 증가율이 10 초과하면 트리거.
Packet drops detected on {{ $labels.instance }}. Total drops: {{ $value }}."
Dart
복사
•
alerts.yml(전체)
groups:
- name: couponService
rules:
- alert: ServiceDown
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Service Down 서비스다운 경고"
description: "1분 동안 상태가 down이면 트리거.
The service {{ $labels.job }} on {{ $labels.instance }} is not responding (status: down)."
- alert: HighCPUUsage
expr: clamp(1 - (sum(rate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) / sum(rate(node_cpu_seconds_total[5m])) by (instance)), 0, 1) * 100 > 80
for: 1m
labels:
severity: warning
annotations:
summary: "High CPU Usage Detected CPU 사용률 경고"
description: "초당 CPU 사용률 80% 초과하면 트리거.
CPU usage of {{ $labels.instance }} has exceeded 80% for the last minute. Current value: {{ $value }}%"
- name: NetworkAlerts
rules:
- alert: HighNetworkTraffic
expr: rate(node_network_receive_bytes_total[5m]) + rate(node_network_transmit_bytes_total[5m]) > 100000000
for: 1m
labels:
severity: critical
annotations:
summary: "High Network Traffic 네트워크 트래픽 과다 경고"
description: "5분 동인 송수신 바이트 초당 증가율이 100MB/s 초과하면 트리거.
Network traffic on {{ $labels.device }} exceeds 100 MB/s. Current rate: {{ $value }}."
- alert: NetworkErrors
expr: (rate(node_network_receive_errs_total[5m]) + rate(node_network_transmit_errs_total[5m])) > 10
for: 1m
labels:
severity: critical
annotations:
summary: "High Network Errors 네트워크 에러 경고"
description: "5분 동안 송수신 네트워크 오류의 초당 증가율이 10 초과하면 트리거.
Network errors detected on {{ $labels.instance }}. Total errors: {{ $value }}."
- alert: NetworkPacketDrops
expr: (rate(node_network_receive_drop_total[5m]) + rate(node_network_transmit_drop_total[5m])) > 10
for: 1m
labels:
severity: warning
annotations:
summary: "High Network Packet Drops 네트워크 드롭 경고"
description: "5분 동안 송수신 패킷 드롭의 초당 증가율이 10 초과하면 트리거.
Packet drops detected on {{ $labels.instance }}. Total drops: {{ $value }}."
Dart
복사
2.
알림 규칙 작성 후 Prometheus와 Alertmanager 를 재가동한다.
docker-compose restart
Dart
복사
3.
알림 설정이 적용 되었는지 확인한다.
•
Prometheus 웹 UI
Alerts 메뉴에서 확인
.png&blockId=16b3ab0d-2170-80c3-b518-cdcc4ba048da)
•
Grafena
Alerting > Alert rules
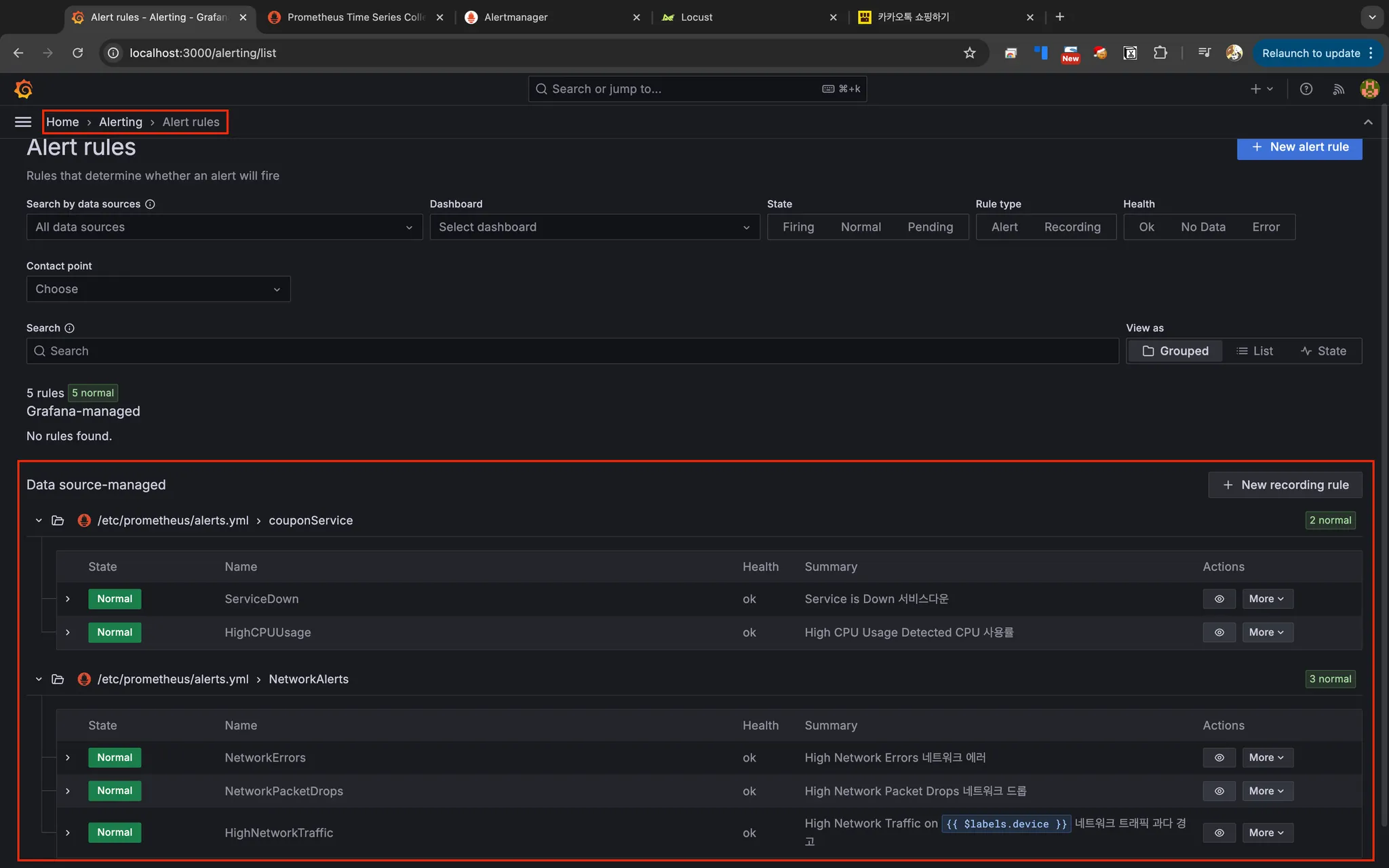
테스트 진행
Service Down 서비스 다운 경고
규칙 내용 확인
서비스의 상태가 down(up==0)으로 1분 이상 지속 될 경우 알림이 전송된다.
up == 0
Dart
복사
테스트 진행
coupon-project 디렉토리에서 서비스가 정의 된 docker-compose를 다운시킨다.
docker-compose down
Dart
복사
확인
•
대시보드 확인
•
모니터링 도구 확인
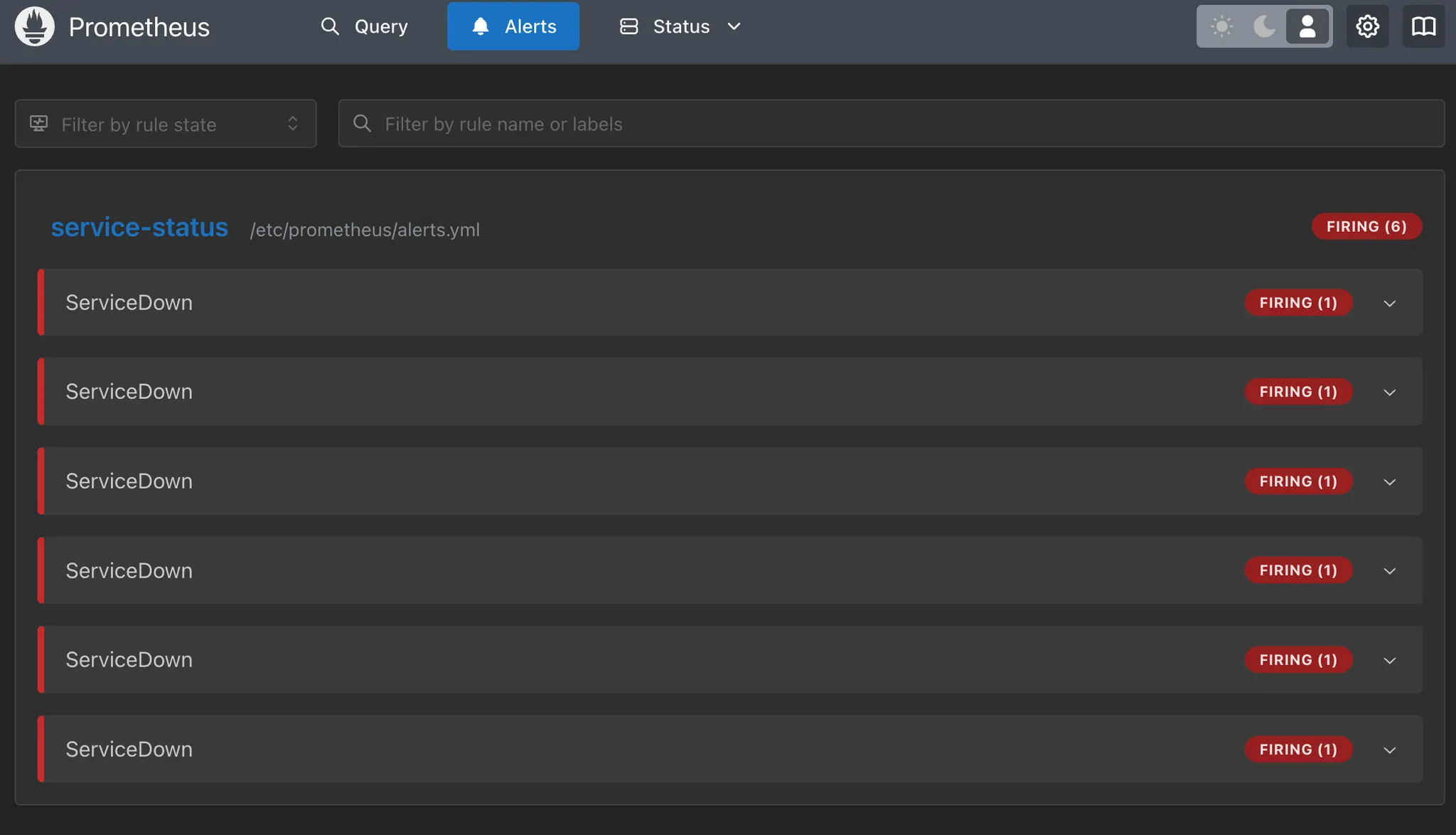
Promethues 웹 UI
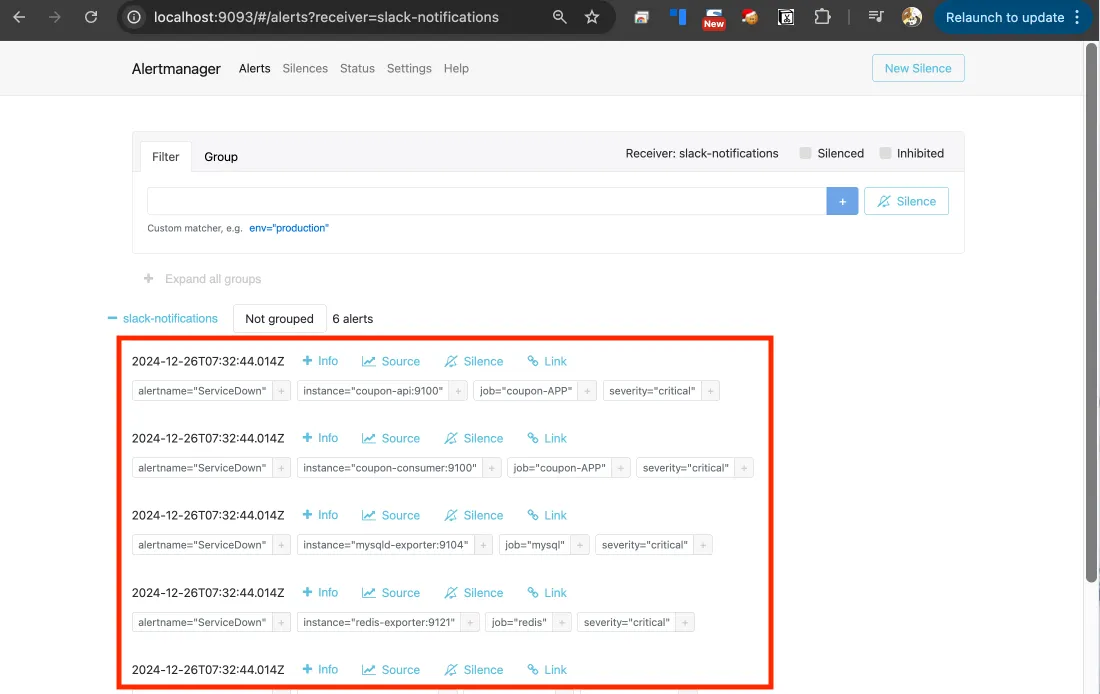
Alertmanager 웹 UI
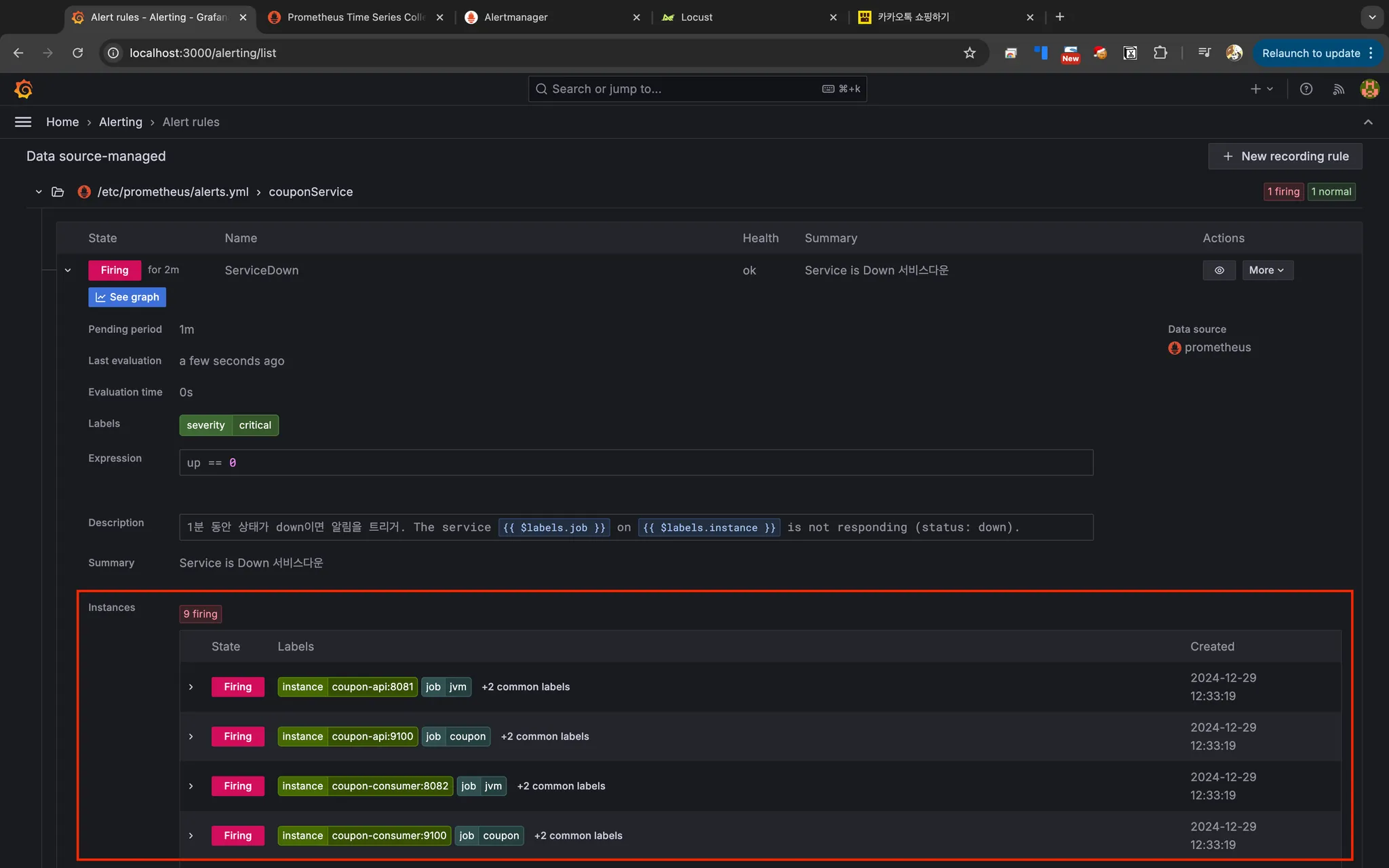
Grafana Alert rules (firing 상태)
•
Slack 메신저 확인
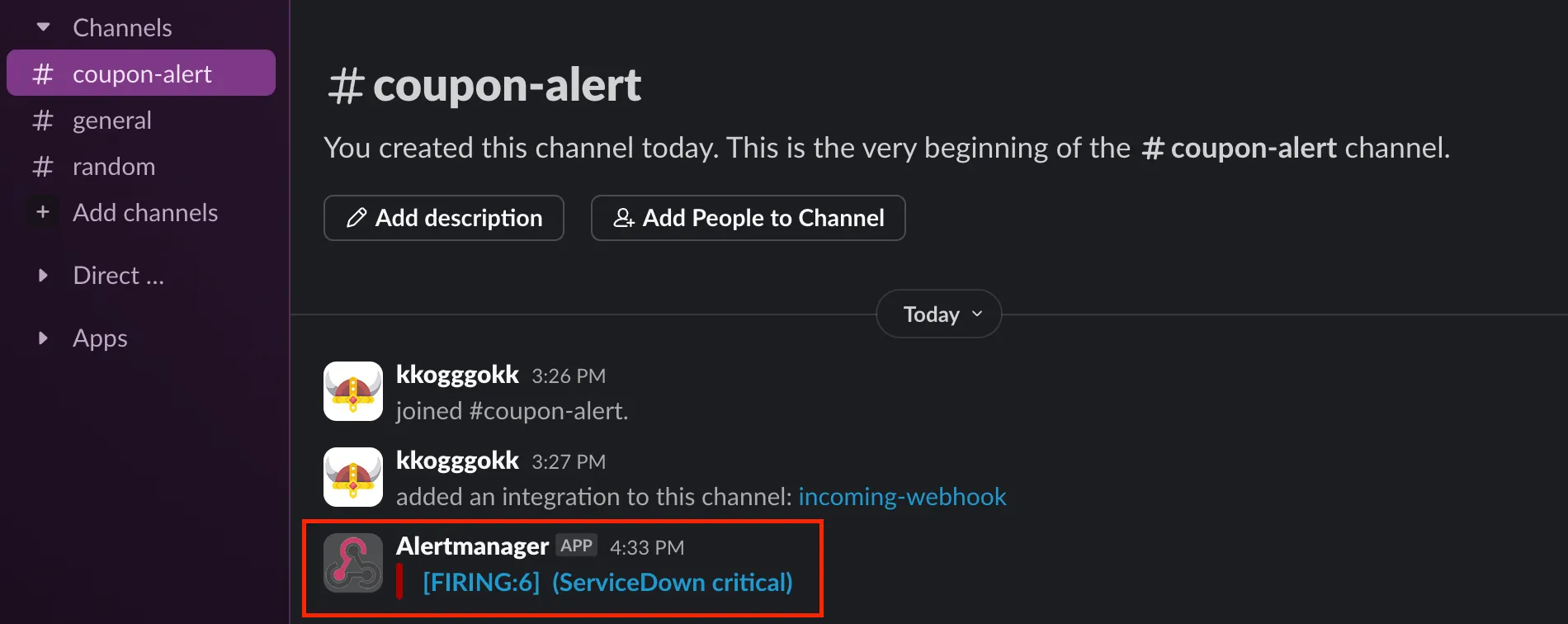
High Network Traffic 네트워크 트래픽 과다 경고
규칙 내용 확인
•
High Network Traffic 네트워크 트래픽 과다 경고
임계값: 초당 100MB (100,000,000 바이트)
rate(node_network_receive_bytes_total[5m]) + rate(node_network_transmit_bytes_total[5m]) > 100000000
Dart
복사
테스트 진행
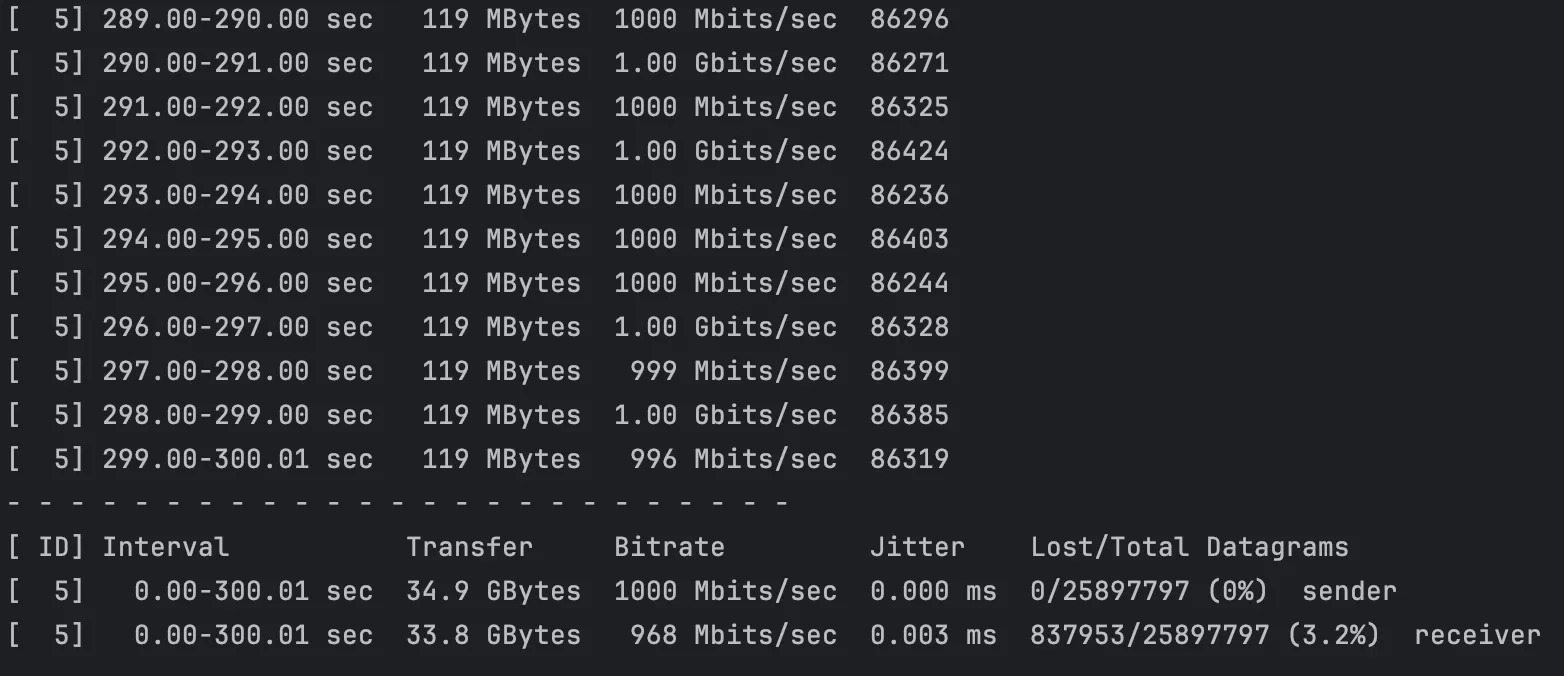
iperf3는 네트워크 성능 테스트를 위해 설계된 도구로, 대량의 송수신 트래픽을 생성할 수 있다.
0.
서버와 클라이언트 둘다 패키지 설치
apt-get install -y iperf3
Dart
복사
서버 설정 (172.18.0.10)
1.
네트워크 테스트 서버를 실행한다.
iperf3 -s
Dart
복사
3.
테스트 종료 후 시뮬레이션 설정을 삭제하여 네트워크를 복구한다.
# 설정 제거
tc qdisc del dev eth0 root
# 설정 제거 확인
tc qdisc show dev eth0
Bash
복사

클라이언트 설정
2.
서버와 통신하며 네트워크 트래픽 부하를 생성한다.
# 클라이언트에서 1Gbps 트래픽 생성
iperf3 -c <server-ip> -u -b 1G
iperf3 -c 172.18.0.10 -u -b 1G -t 300
Dart
복사
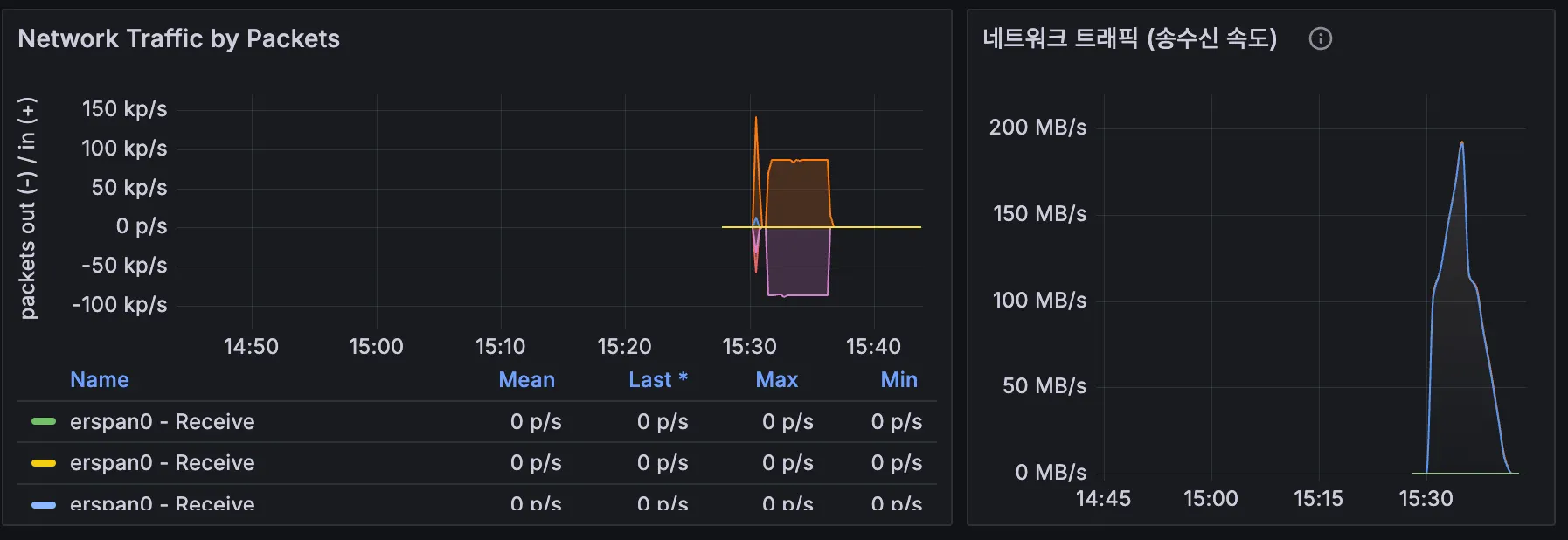
확인
•
대시보드 확인
•
모니터링 도구 확인
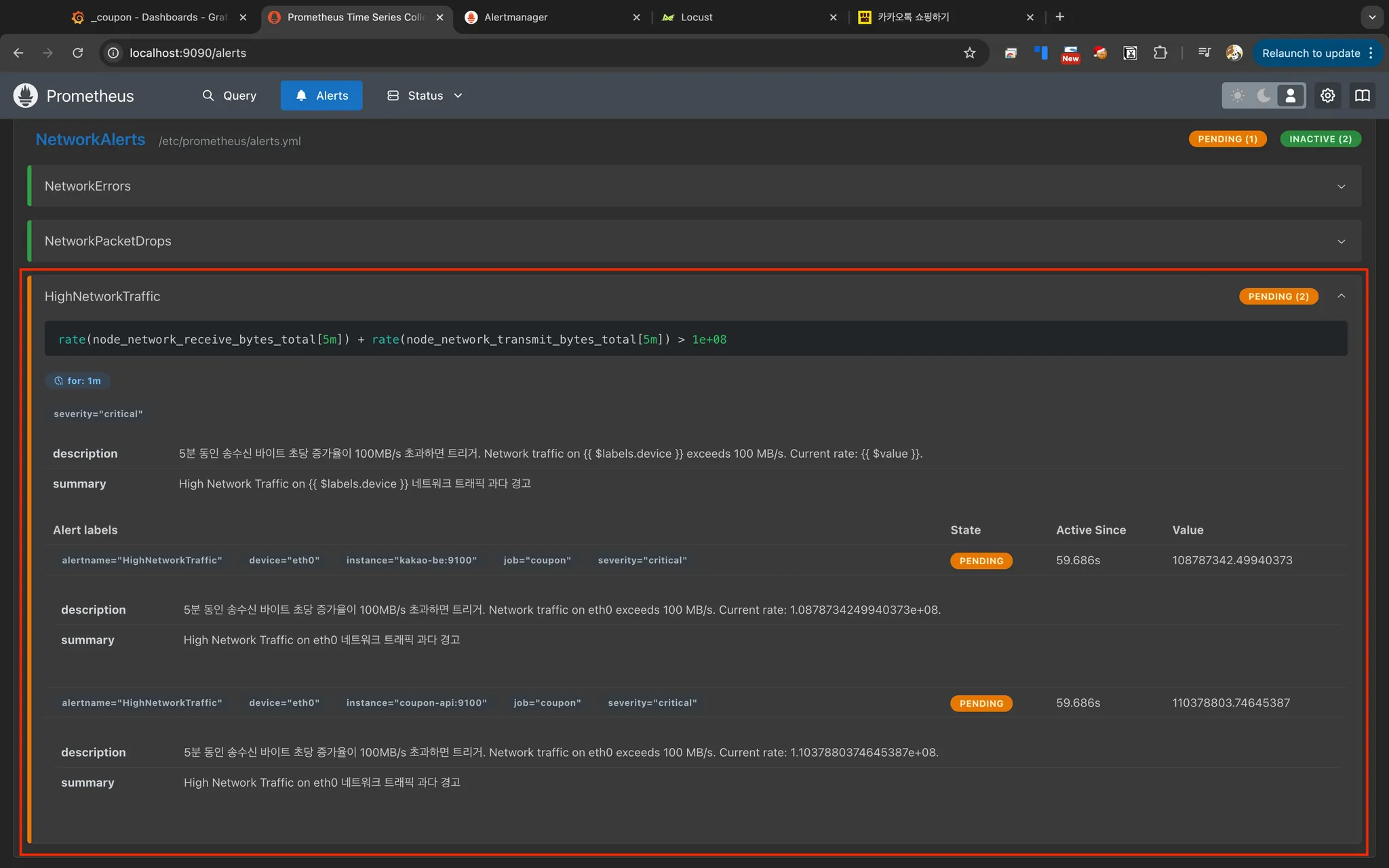
Promethues 웹 UI

Alertmanager 웹 UI
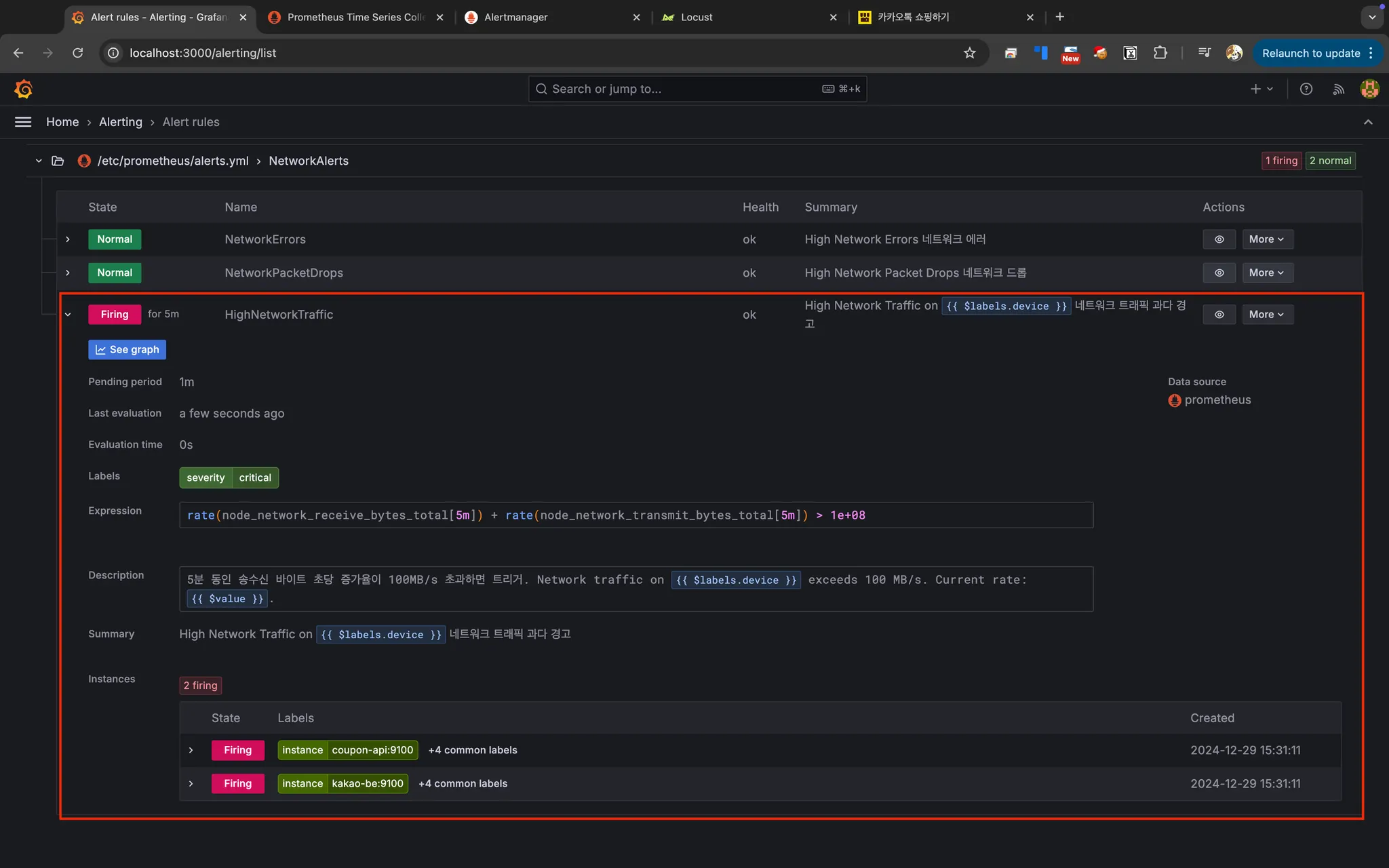
Grafana Alert rules
•
Slack 메신저 확인
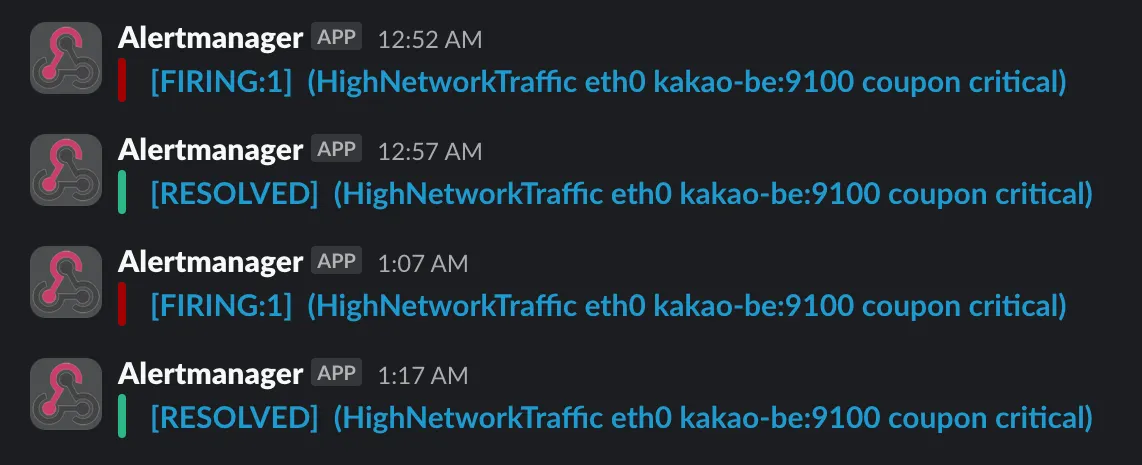
4. NetworkErrors + Drop
규칙 내용 확인
•
NetworkErrors 네트워크 에러 경고
임계값: 송수신 초당 에러 10개 초과
(rate(node_network_receive_errs_total[5m]) + rate(node_network_transmit_errs_total[5m])) > 10
Dart
복사
•
NetworkErrors 네트워크 에러 경고
임계값: 송수신 초당 드롭된 패킷 수가 10개 초과
(rate(node_network_receive_drop_total[5m]) + rate(node_network_transmit_drop_total[5m])) > 10
Bash
복사
테스트 진행
tc와 iperf3를 활용하여 네트워크 에러를 시뮬레이션한다.
서버 설정(172.18.0.10)
1.
네트워크 제어 권한이 필요하므로 도커 컨테이너를 실행 시 NET_ADMIN 권한을 부여한다.
# 도커 컨테이너로 실행 시
docker run --cap-add=NET_ADMIN --network coupon-network --rm -it coupon-api /bin/bash
# 도커 컴포즈 형태로 실행 시
coupon-api:
image: coupon-api:latest
build:
context: ./coupon-BE
dockerfile: ./Dockerfile-couponAPI
container_name: coupon-api
networks:
- coupon-network
cap_add:
- NET_ADMIN # NET_ADMIN 권한 추가
Dart
복사
2.
네트워크 시뮬레이션 및 상태 확인을 위해 tc와 관련된 패키지를 설치한다.
apt-get install -y iproute2 iputils-ping net-tools iftop
Dart
복사
3.
tc 명령어를 사용하여 송수신 패킷에 에러를 추가한다.
# 패킷 손상 시뮬레이션 추가
tc qdisc add dev eth0 root netem corrupt 50%
# 설정 확인
tc qdisc show dev eth0
Dart
복사

4.
네트워크 테스트 서버를 실행한다.
iperf3 -s
Dart
복사
5.
테스트 종료 후 시뮬레이션 설정을 삭제하여 네트워크를 복구한다.
# 설정 제거
tc qdisc del dev eth0 root
# 설정 제거 확인
tc qdisc show dev eth0
Bash
복사

클라이언트 설정
5.
서버와 통신하며 네트워크 트래픽 부하를 생성한다.
iperf3 -c 172.18.0.10 -t 300
Dart
복사

확인
•
대시보드 확인
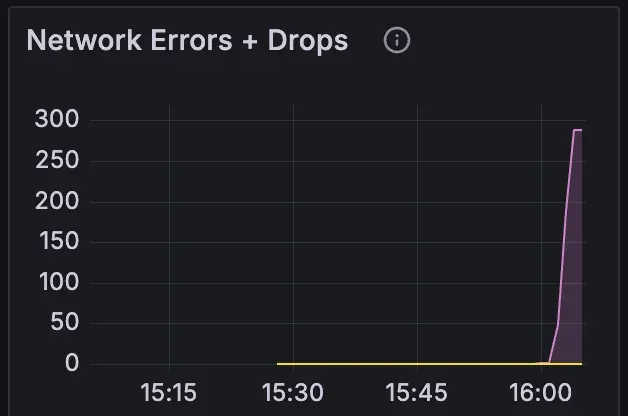
•
모니터링 도구 확인
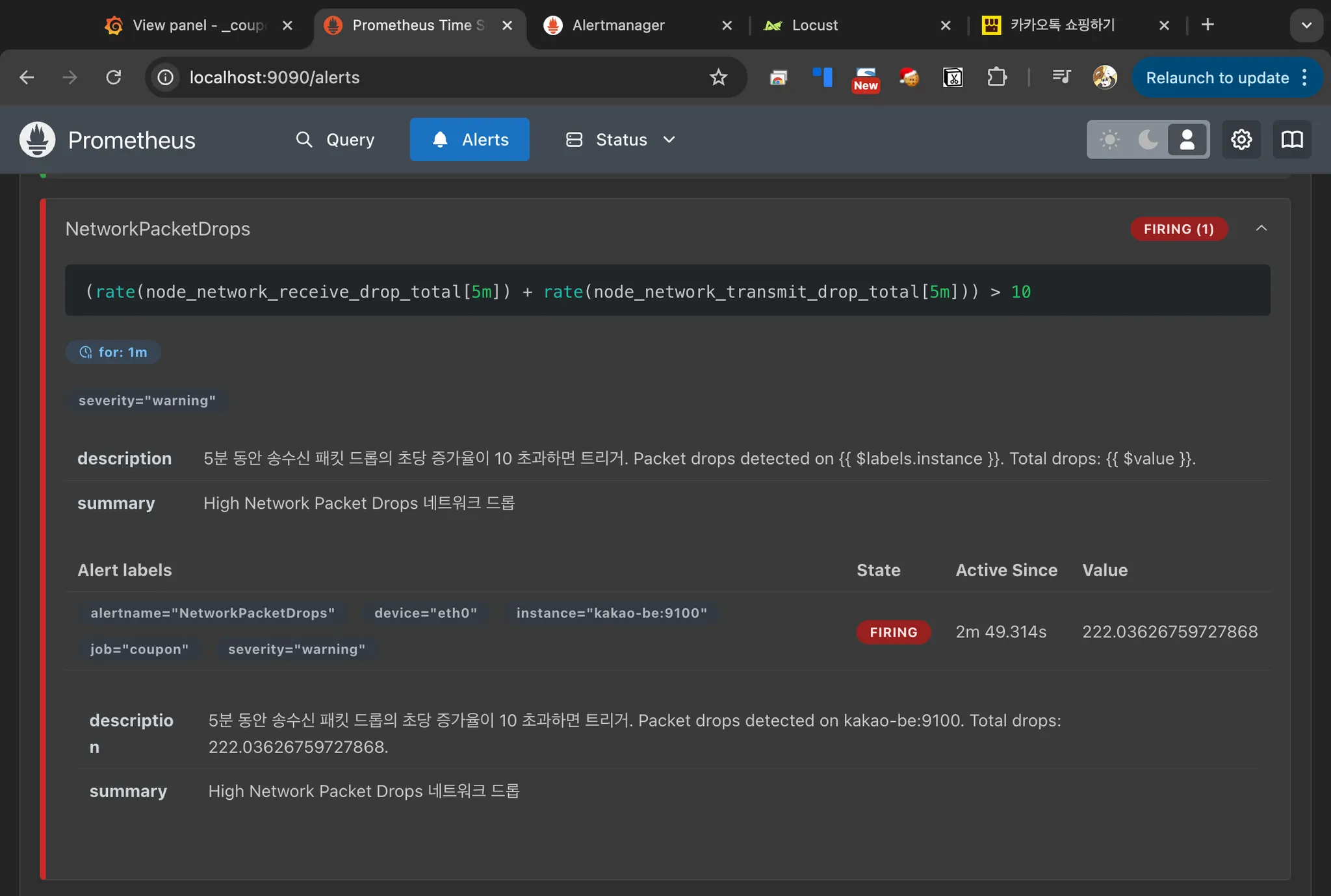
Promethues 웹 UI
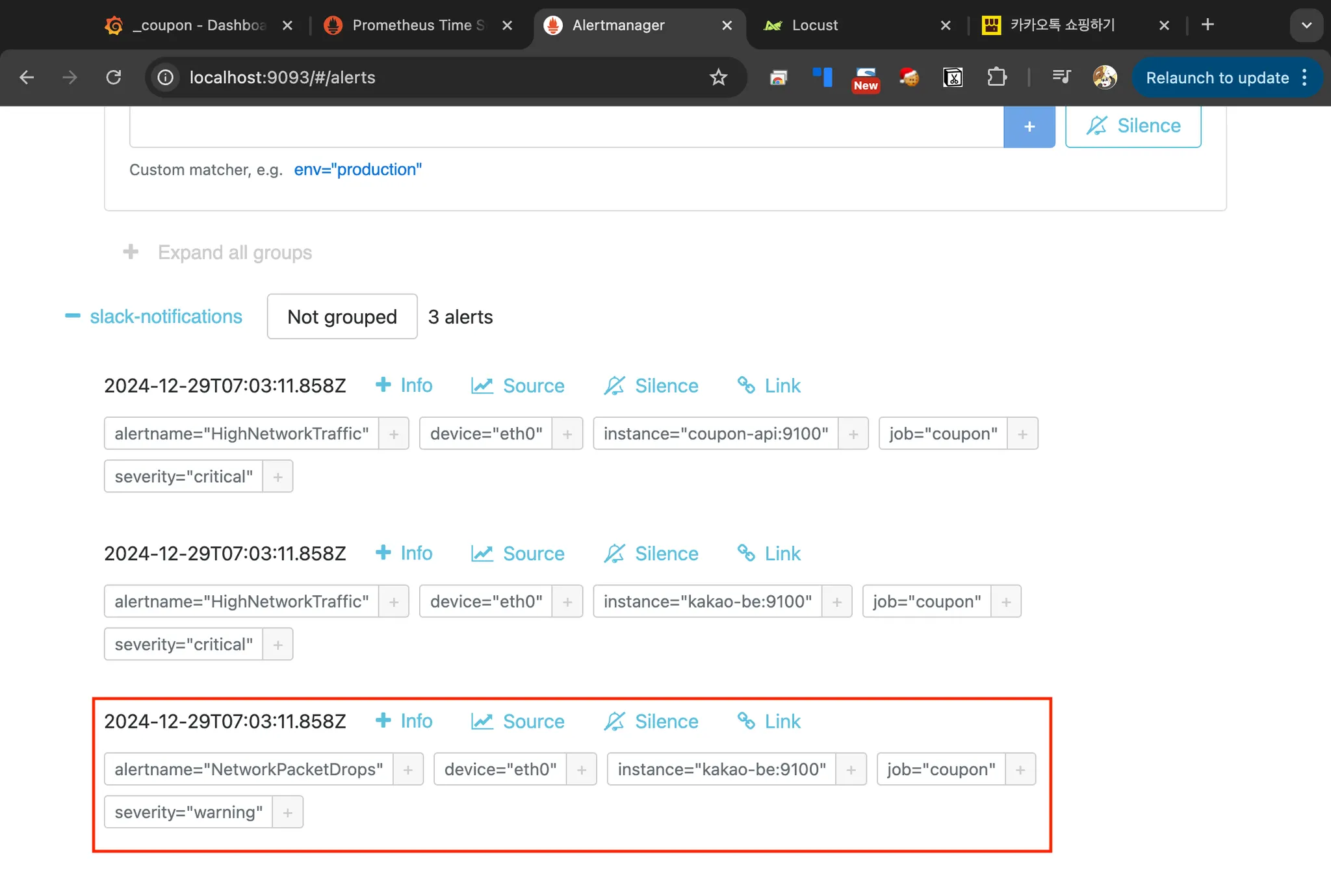
Alertmanager 웹 UI
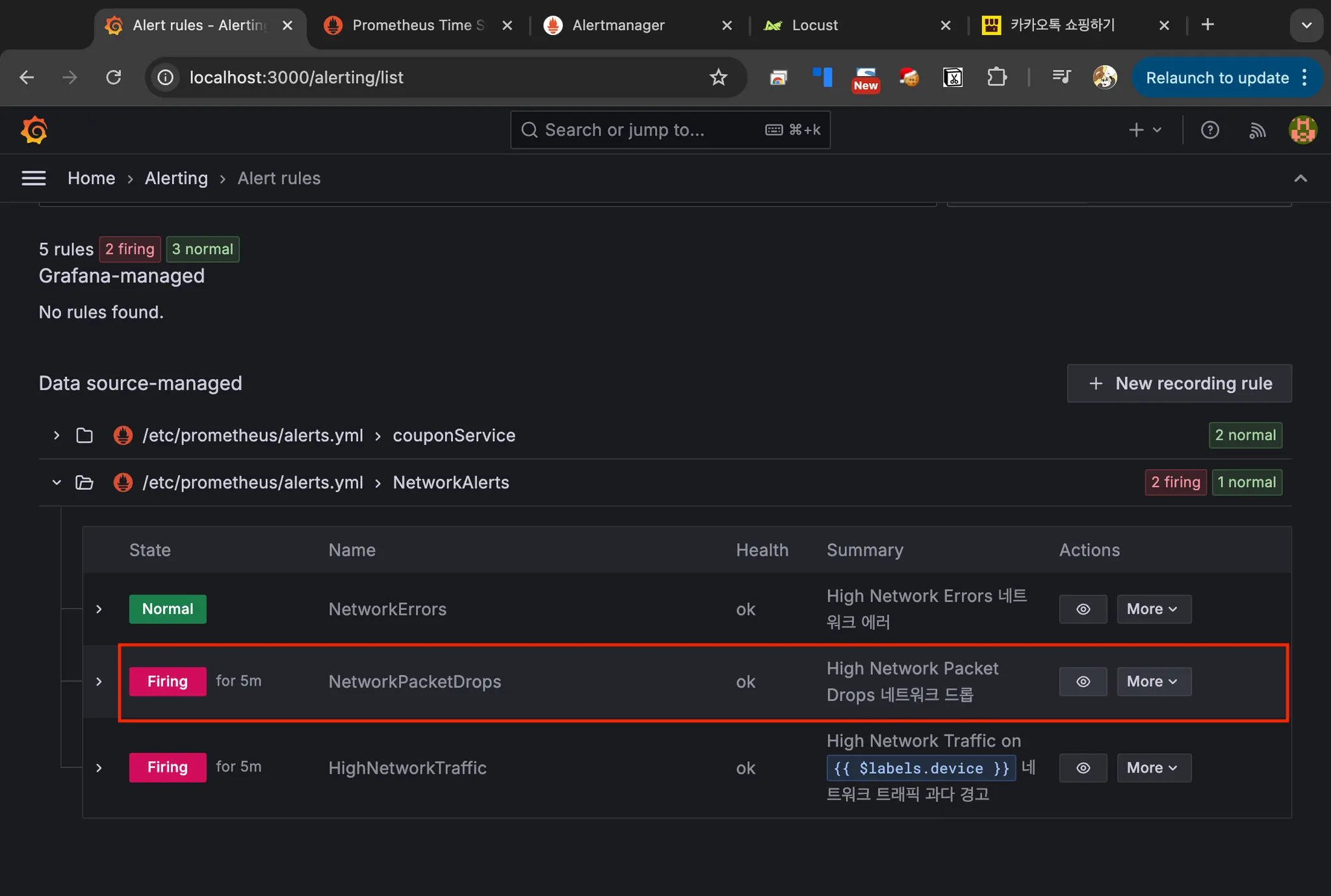
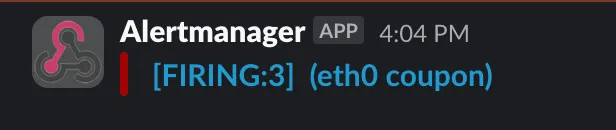
Grafana Alert rules
•
Slack 메신저 확인
결론
Alertmanager Rule 설정은 시스템의 상태와 성능을 모니터링하고, 사전에 정의된 임계값 초과 시 실시간으로 알림을 전송하는 데 필수적이다. 서비스 상태(ServiceDown), CPU 사용률(HighCPUUsage), 네트워크 트래픽(HighNetworkTraffic), 네트워크 오류(NetworkErrors) 등의 다양한 조건에 따른 알림을 정의함으로써 시스템 관리자와 운영팀이 문제를 신속히 인지하고 조치할 수 있는 기반을 제공한다. 이로써 시스템 가용성과 안정성을 강화하고, 문제 발생 시 복구 시간을 단축할 수 있다.
Q&A
네트워크 테스트에 사용된 도구
Related Posts
Search