




Alertmanager
Prometheus 알림 시스템
Prometheus 알림 시스템은 2가지 주요 구성 요소로 나뉜다.
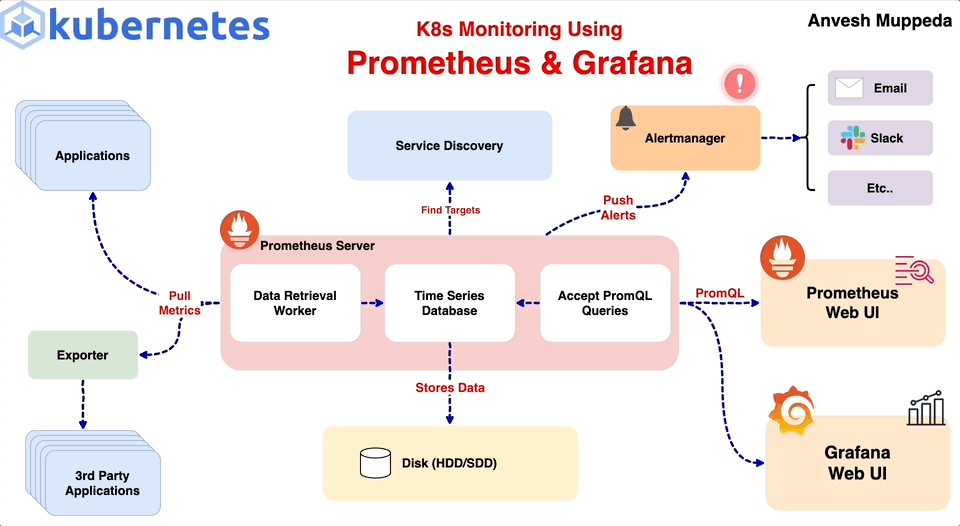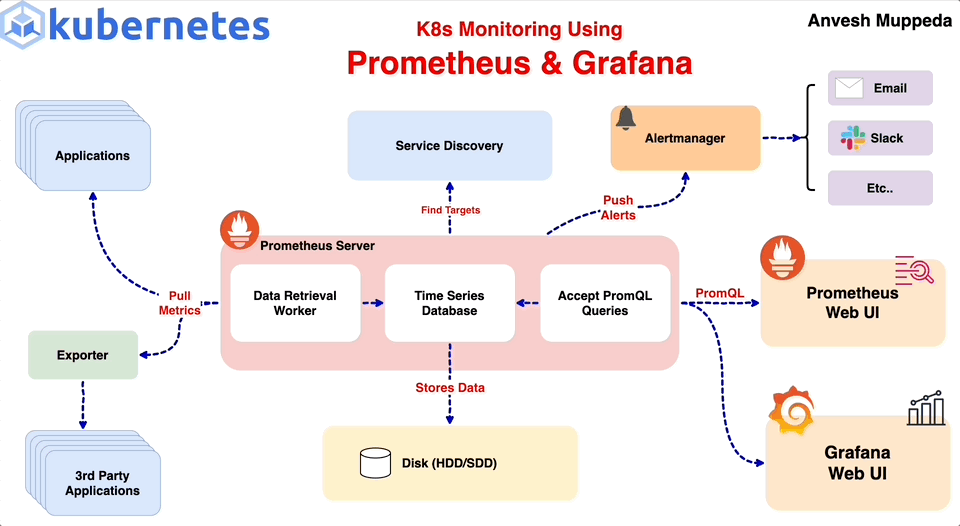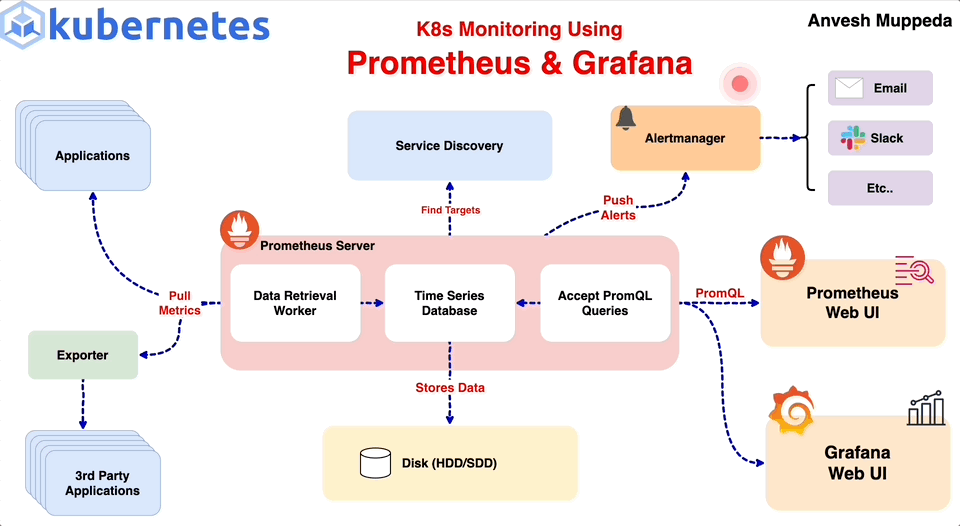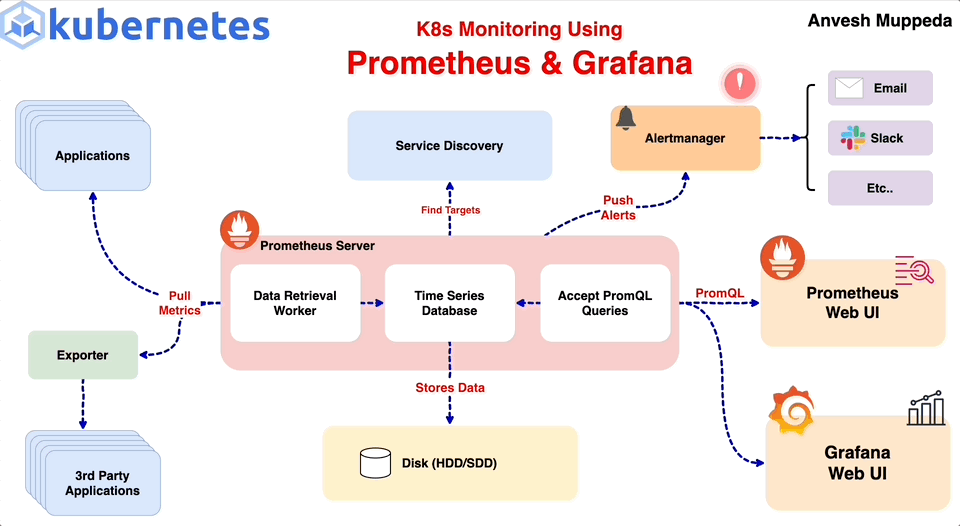
1.
알림 규칙(Alerting Rules)
Prometheus 서버는 특정 조건이 충족될 경우 경고(alert)를 생성하여 Alertmanager로 전송한다.
2.
알림 관리(Alertmanager)
Prometheus 서버 및 기타 클라이언트 애플리케이션에서 전송된 알림(alert)을 관리한다.
다음과 같은 작업을 수행한다.
•
Silencing: 특정 경고를 일시적으로 비활성화
•
Inhibition: 다른 경고에 의해 특정 경고를 억제
•
Aggregation: 여러 경고를 하나로 묶어서 처리
•
Notifications: 이메일, 온콜 시스템, 채팅 플랫폼(Slack 등)을 통해 알림 전송
Alertmanager 구조
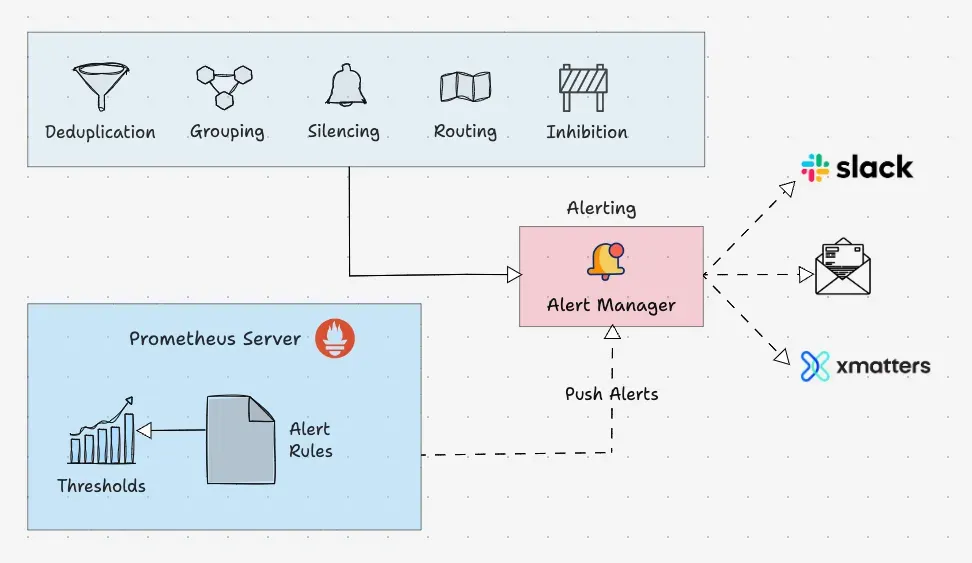
Alertmanager 설정
•
Alertmanager를 설치하고 구성 파일(alertmanager.yml)을 통해 알림 대상(예: Slack, 이메일 등)을 설정한다.
•
알림의 경로(route)와 수신자(receivers)를 정의한다.
global:
resolve_timeout: 5m
slack_api_url: 'https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK'
route:
receiver: 'slack-notifications'
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#alert'
send_resolved: true
YAML
복사
alertmanger.yml (Alermanger 설정 예시)
Prometheus 와 Alertmanager 연동
•
Prometheus 설정 파일(prometheus.yml)에서 Alertmanager와의 통신 설정을 추가한다.
•
Alertmanager의 네트워크 경로를 지정하여 경고를 전달할 수 있도록 한다.
alerting:
alertmanagers:
- static_configs:
- targets:
- 'alertmanager:9093'
rule_files:
- "alerts.yml"
YAML
복사
prometheus.yml (Prometheus, alertmanger 연동 예시)
Prometheus 알림 규칙(Alerting Rules) 작성
•
Prometheus 설정 파일에서 규칙 파일(alerts.yml)을 지정한다.
•
경고 조건을 작성하여 특정 메트릭스가 조건을 충족하면 Alertmanager로 경고를 전송하도록 설정한다.
groups:
- name: example
rules:
- alert: HighCPUUsage
expr: node_cpu_seconds_total > 0.8
for: 1m
labels:
severity: warning
annotations:
summary: "High CPU usage detected"
description: "The CPU usage has exceeded 80% for the past minute."
YAML
복사
alerts.yml (알림 규칙 예시)
Alertmanager 주요 기능
기능 | 설명 |
Grouping | 비슷한 성격의 알림을 하나의 알림으로 그룹화하여 관리 |
Inhibition | 특정 경고가 이미 발생한 경우 관련 없는 경고 알림을 억제 |
Silences | 특정 조건의 경고를 지정된 시간 동안 음소거 |
Client Behavior | Prometheus 외 다른 클라이언트에서 Alertmanager로 알림을 전송할 경우 특별한 동작 요구 |
High Availability | 고가용성을 위해 Alertmanager 클러스터를 구성 |
1. Grouping (그룹화)
•
기능: 동일한 성격의 알림을 하나로 묶어 단일 알림으로 보냄.
•
활용: 대규모 장애 발생 시, 관련된 수백 또는 수천 개의 알림을 단일 알림으로 축약하여 수신.
•
구성 방법:
◦
Alertmanager의 라우팅 트리(routing tree)를 통해 그룹화 설정.
◦
그룹화 기준과 알림 전송 간격(timing)을 설정.
2. Inhibition (억제)
•
기능: 특정 알림이 발생 중일 때, 다른 관련 알림을 억제.
•
활용: 클러스터 전체가 다운되었을 때, 개별 서비스 경고를 억제하여 과도한 알림 방지.
•
구성 방법:
◦
Alertmanager 구성 파일에서 설정.
◦
억제 조건은 특정 경고와 관련된 다른 경고를 정의.
3. Silences (음소거)
•
기능: 특정 조건의 알림을 일정 시간 동안 차단.
•
활용: 유지보수 중 불필요한 알림을 비활성화.
•
구성 방법:
◦
Alertmanager의 웹 인터페이스에서 매처(matchers) 기반으로 설정.
4. Client Behavior (클라이언트 동작)
•
설명: Prometheus가 아닌 클라이언트에서 Alertmanager와 통신 시 특수 요구 사항.
•
활용: 고급 사용 사례에서 비 Prometheus 클라이언트 사용 가능.
5. High Availability (고가용성)
•
기능: Alertmanager 클러스터를 통해 장애를 대비.
•
활용:
◦
Alertmanager를 여러 노드로 구성하고, Prometheus에서 모든 노드로 직접 알림 전송.
◦
구성 주의: 로드 밸런서를 사용하지 말고, Prometheus가 Alertmanager의 모든 노드에 직접 접근해야 함.
마무리
Alertmanager는 Prometheus와 긴밀한 통합을 통해 대규모 시스템 모니터링에서 발생하는 경고를 효과적으로 관리하고, 알림의 정확성과 효율성을 높인다. 그룹화와 억제를 통해 불필요한 알림을 줄이고, 고가용성을 통해 신뢰성을 보장한다.
Related Posts
Search

















